
TI 的 TDA4VM SoC 包含双核 A72、高性能视觉加速器、视频编解码器加速器、最新的 C71x 和 C66x DSP、用于捕获和显示的高带宽实时 IP、GPU、专用安全岛和安全加速器。SoC 经过功率优化,可为机器人、工业和汽车应用中的感知、传感器融合、定位和路径规划任务提供一流的性能。TDA4VM Edge AI Starter Kit (SK) 是一款低成本、小尺寸板,功耗大约20W,能提供8TOPS深度学习算力,支持Tensorflow Lite,ONNX,TVM,GStreamer接口
TDA4开发(一) soc介绍
Preface

TDA4VM SK
运行前准备
•SK板
•USB camera •支持HDMI或者DP口的显示器 •至少16GB空间SD卡,如果大于16G,需要手动拓展 root filesystem
•网线和局域网
•串口电源(5-20V DC),功率保证20W以上 如果功率不够,运行期间可能导致重启
设置启动模式
将拨码开关拨到如图所示位置,系统从SD卡启动

支持的相机输入
USB Camera
驱动已经在SDK中解决了,根据文档说明,已经测试过C270/C920/C922三款camera,如果遇到camera打不开的情况参考文档[1]
YUV sensor
支持OV5640,200万像素,CSI接口,YUYV输出,产品信息[2]默认在SDK中,OV5640是被屏蔽的,需要手动开启支持打开/run/media/mmcblk0p1/uenv.txt
然后编辑
1 | name_overlays=k3-j721e-edgeai-apps.dtbo k3-j721e-sk-csi2-ov5640.dtbo |
重启设备即可
Raw sensor
RPiV2
软件设置
下载SDK包[3]
下载烧录软件[4]
烧录软件使用1.7.0版本烧录完成即可上电启动
先插入SD卡,然后再上电,显示器就会有如下图所示画面,代表启动成功

板子默认在串口打印日志,所以初次上电需要连接串口,登陆账号
串口使用
在host ubuntu上推荐安装minicom,minicom使用方法参考[5]
在windows上推荐安装teraterm[6]
ubuntu下启动minicom
1 | sudo minicom -D /dev/ttyUSB2 -c on |
板子默认串口波特率是115200 连接串口登陆用户名是root,不需要密码进去之后,ifconfig查询板子ip地址,后面即可使用ssh登陆
推荐使用vscode,可以利用remote插件来直接ssh登陆到板子,然后可以很方便地修改配置文件
配置软件环境
软件环境配置才是重点,例如安装tensorflow,onnx,python和c++依赖库
1 | /opt/edge_ai_apps#./setup_script.sh |
运行上面脚本,所有环境自动安装
•clone Tensoflow•clone ONNX-RT•clone edgeai-tiovx-modules•clone edgai-gst-plugins•clone adgeai-tidl-tools•compile C++ apps
经常会遇到运行失败,原因就是访问github比较慢,多试几次就好
如果需要调试相关环境,直接在运行的时候,加入参数,即可编译debug版本
1 | root@j7-evm:/opt/edge_ai_apps#./setup_script.sh -d |
References
[1] 参考文档: https://software-dl.ti.com/jacinto7/esd/processor-sdk-linux-sk-tda4vm/latest/exports/docs/faq.html#pub-edgeai-multiple-usb-cams[2] 产品信息: https://www.leopardimaging.com/product/cmos-sensor-modules/mipi-camera-modules/li-am65x-csi2[3] SDK包: https://dr-download.ti.com/software-development/software-development-kit-sdk/MD-4K6R4tqhZI/08.02.00.02/ti-processor-sdk-linux-sk-tda4vm-etcher-image.zip[4] 烧录软件: https://github.com/balena-io/etcher/releases/tag/v1.7.0[5] minicom使用方法参考: https://help.ubuntu.com/community/Minicom[6] teraterm: https://learn.sparkfun.com/tutorials/terminal-basics/tera-term-windows
TDA4开发(二) 运行demo
原创 carpenter 卡本特 2022-07-08 20:30 发表于广东
收录于合集#Ti-tda44个
运行板载demo
Ti在板载端提供了非常丰富的demo,每个demo都提供了输入文件,模型文件。只需要修改config文件运行即可,demo分为python版本和c++版本,C++版本的运行效率会稍微高一些
配置文件
配置文件通过使用YAML格式来设置参数,配置文件路径为edge_ai_app/configs
在配置文件中指定了demo运行的输入类型,例如picture, video, camera
还可以指定加载模型的路径,指定输出类型,例如是保存到本地文件还是输出到显示器
如下图所示
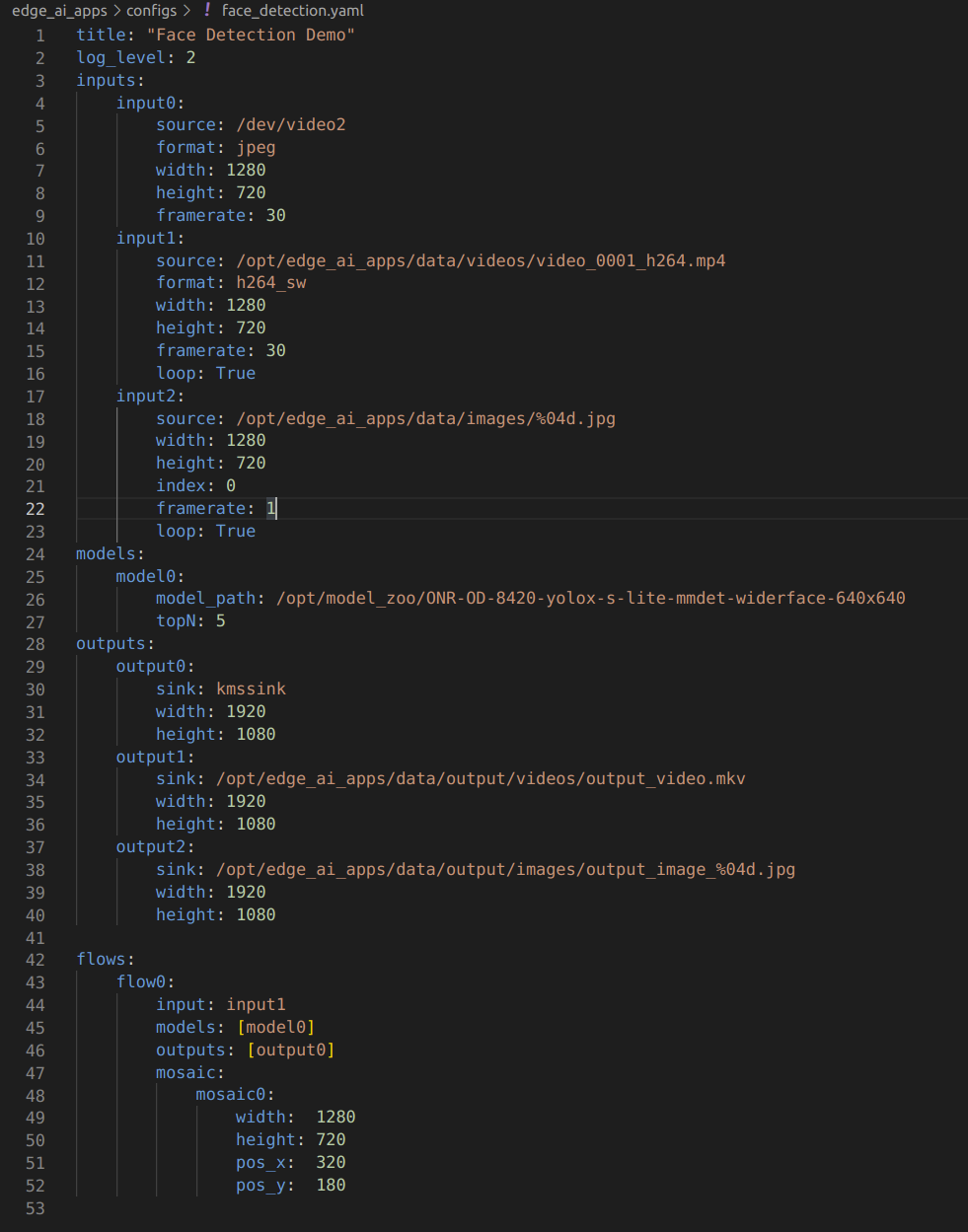
config 文件分为四个部分
•Inputs
•Models
•Outputs
•Flows
Inputs
1 | inputs: input0: #Camera Input source: /dev/video2 #Device file entry of the camera format: jpeg #Input data format suported by camera width: 1280 #Width and Height of the input height: 720 framerate: 30 #Framerate of the source |
1, Camera
挂载到板子上的camera会被v4l2src GStreamer来作解析,是否会被识别为camera,需要使用脚本来验证
1 | ./init_script.sh |
如果插上的camera能够成功被识别,那么会有如下输出
1 | root@j7-evm:/opt/edge_ai_apps# ./init_script.shUSB Camera detected device = /dev/video2 format = jpeg |
2, Video
支持H264和H265格式
1 | input1: source: ../data/videos/video_0000_h264.mp4 format: h264 width: 1280 height: 720 framerate: 25 |
如果不确定某个视频文件具体的视频流格式,那么可以在format设置为auto, 可以被Gstreamer自动解码识别
3, Images
可以配置输入为多张图片,指定图片文件夹路径即可
1 | input2: source: ../data/images/%04d.jpg width: 1280 height: 720 index: 0 framerate: 1 |
4, RTSP stream
GStreamer可以解析来自于RTSP数据源非加密数据
1 | input0: source: rtsp://172.24.145.220:8554/test # rtsp stream url, replace this with correct url width: 1280 height: 720 framerate: 30 |
Models
配置推理模型的相关参数,包括模型路径,和模型参数,例如阈值。在anchor based的目标检测算法中可能有topN参数,在segmentation中有alpha参数, 不同类型的模型需要的配置参数不同
1 | models: model0: model_path: ../models/segmentation/ONR-SS-871-deeplabv3lite-mobv2-cocoseg21-512x512 #Model Directory alpha: 0.4 #alpha for blending segmentation mask (optional) model1: model_path: ../models/detection/TFL-OD-202-ssdLite-mobDet-DSP-coco-320x320 viz_threshold: 0.3 #Visualization threshold for adding bounding boxes (optional) model2: model_path: ../models/classification/TVM-CL-338-mobileNetV2-qat topN: 5 #Number of top N classes (optional) |
Outputs
可以配置为显示器输出,保存为视频文件,输出为图片
1 | outputs: output0: #Display Output sink: kmssink width: 1920 #Width and Height of the output height: 1080 connector: 39 #Connector ID for kmssink (optional) |
1, 显示器输出
支持DP和HDMI的输出,确认显示器是否成功连接
1 | root@j7-evm:/opt/edge_ai_apps# modetest -M tidss -c | grep connected39 38 connected DP-1 530x300 12 3848 0 disconnected HDMI-A-1 0x0 0 47 |
例如上面显示,connector 39是connected状态,所以在配置Output的时候,可以在connector填入39
2,保存本地视频
1 | output1: sink: ../data/output/videos/output_video.mkv width: 1920 height: 1080 |
3,保存为图片
1 | output2: sink: ../data/output/images/output_image_%04d.jpg width: 1920 height: 1080 |
Flows
通过配置Flows可以将不同的input,model,output组合到一起
模型下载
跑完板载的简单demo,可以配置比较复杂的任务了
Ti提供了一个叫做Model Downloader Tool[1]的工具,用来下载不同类型的预训练模型
运行下载器
1 | root@j7-evm:/opt/edge_ai_apps# ./download_models.sh |
是一个可交互界面,可以通过键盘选择想要下载的模型文件,其保存路径在/opt/model/zoo
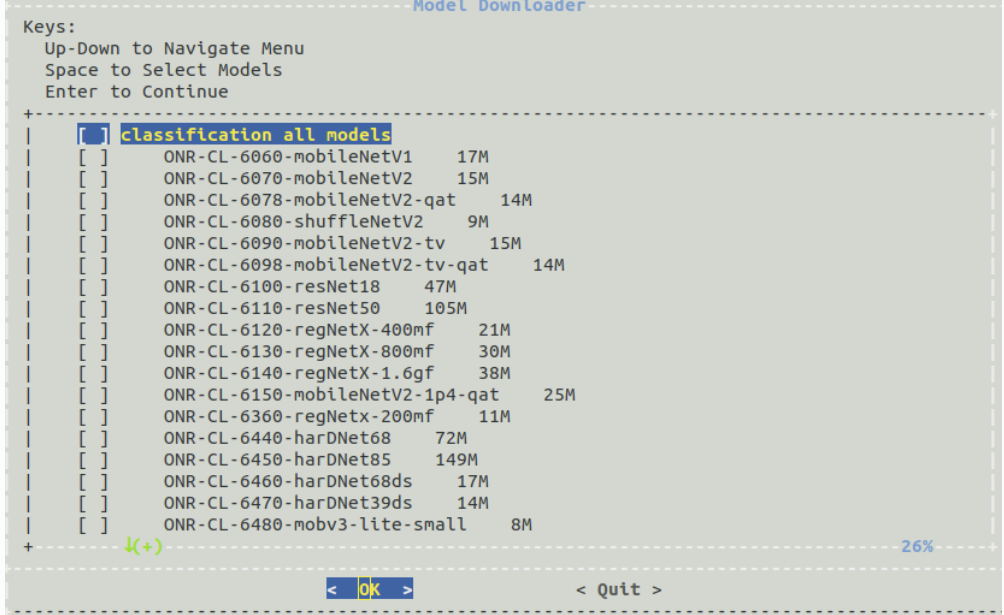
自定义模型
官方提供的模型肯定是不能满足个人业务需求的,所以自己训练模型并导入到tda4运行,是一个必然绕不开的路
Ti SDK提供了加载自定义模型的接口
•Tensorflow Lite•ONNX•TVM/Neo AI-DLR
每一个DNN模型需要满足以下结构
1 | TFL-OD-2010-ssd-mobV2-coco-mlperf-300x300│├── param.yaml│├── artifacts│ ├── 264_tidl_io_1.bin│ ├── 264_tidl_net.bin│ ├── 264_tidl_net.bin.layer_info.txt│ ├── 264_tidl_net.bin_netLog.txt│ ├── 264_tidl_net.bin.svg│ ├── allowedNode.txt│ └── runtimes_visualization.svg│└── model └── ssd_mobilenet_v2_300_float.tflite |
•model
模型文件,例如tflite,onnx等
•artifacts
由SDK编译生成出来的文件,网络层信息,量化信息,节点名称。
此部分是将模型转为TiDL模型中最为关键的一部分,Ti提供专门的文档[2]来解释这部分内容。
•param.yaml 定义前处理,后处理等参数,例如anchor based和anchor free的后处理操作就很大不一样, 例如目标检测和语义分割对应的param格式就不一样,Ti提供了benchmark[3], 可以在里面找到对应的模板
SDK提供了一个工具叫做Edge AI TIDL Tools[4], 可以将通用模型转为Ti支持的DNN模型,目前支持三种模型的转换,但是Ti建议分别使用三种模型尝试转换,哪种模型的精度高就选用哪种模型做最终部署
References
[1] Model Downloader Tool: https://github.com/TexasInstruments/edgeai-modelzoo[2] 文档: https://software-dl.ti.com/jacinto7/esd/processor-sdk-linux-sk-tda4vm/latest/exports/docs/inference_models.html#pub-edgeai-compile-artifacts[3] benchmark: https://github.com/TexasInstruments/edgeai-benchmark/tree/master/examples/configs/yaml[4] Edge AI TIDL Tools: https://github.com/TexasInstruments/edgeai-tidl-tools/blob/master/examples/osrt_python/README.md#model-compilation-on-pc
TDA4开发(三) 运行demo
TiDL-tools
在TDA4上进行inference的时候,主要是跑在A72和C71-MMA异构系统上,并不是单核完成。具体哪些操作在A核哪些操作在DSP核,需要在SDK编译时候配置。
TF-Lite[1]提供了TFLite Delgate API[2], TiDL可以很方便地去调用。ONNX和TVM则是调用标准API
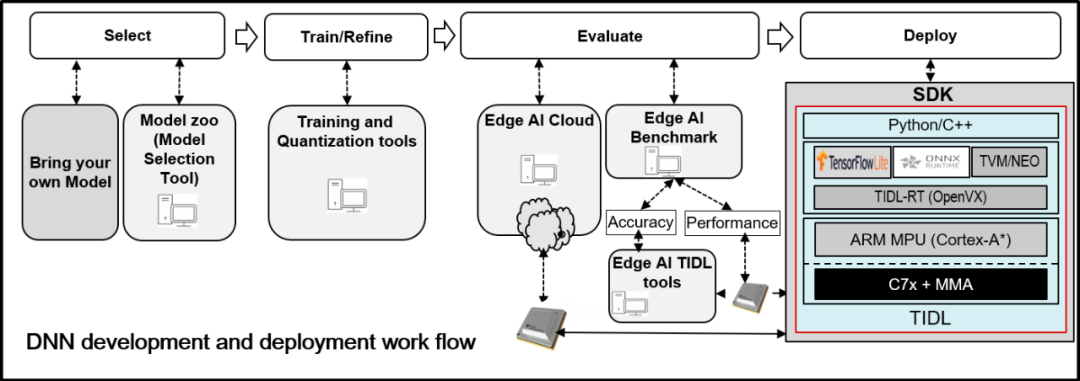
WorkFlow
以TFLite为例,TFLite的模型首先需要在PC上根据SDK生成Artifacts,然后再将模型和artifact一起作为输入,送到soc中完成推理任务
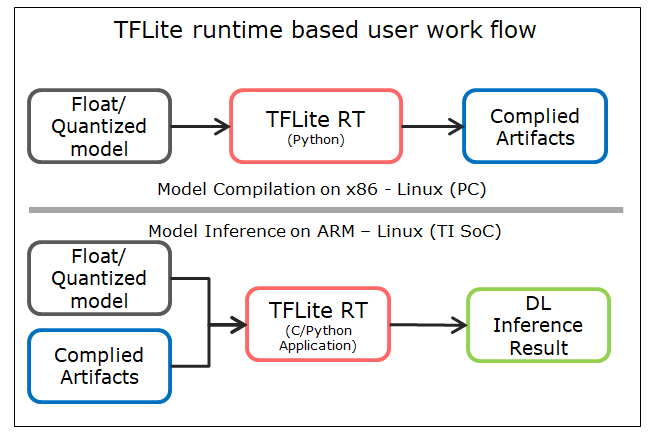
模型转换
1,在PC上搭建环境[3]
建议Ubuntu18.04 + Python3.6, 模型转换只能通过python脚本完成
需要使用pip配置环境,需要先安装pip
1 | sudo apt install python3-pip |
下载代码,然后安装
1 | git clone https://github.com/TexasInstruments/edgeai-tidl-tools.gitexport DEVICE=j7#export DEVICE=am62 #设置DEVICEcd edgeai-tidl-toolssource ./setup.sh |
需要大量下载,时间会比较长
可能会在某个步骤安装出错,需要打开setup.sh,按照终端输出信息来重试几次。
编译ONNX失败
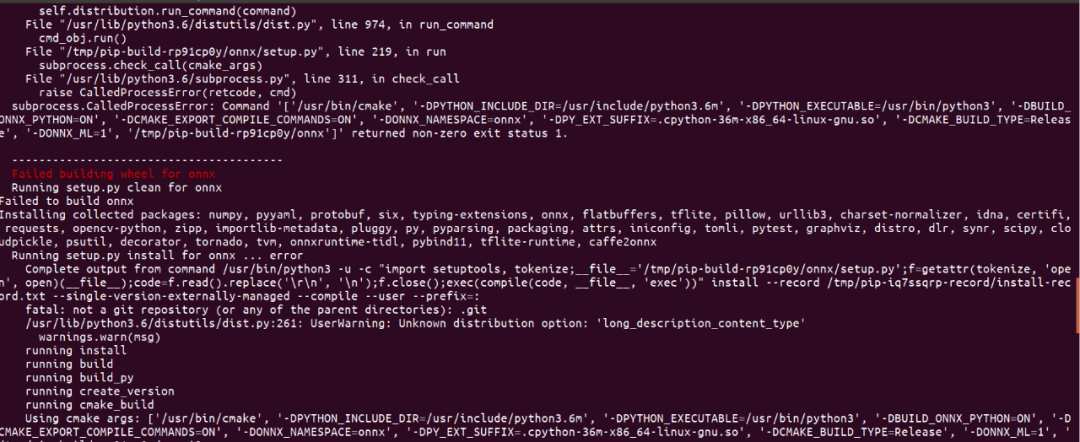
这是因为没有安装proto compillar
1 | sudo apt install protobuf-compiler libprotoc-dev |
成功安装如图所示
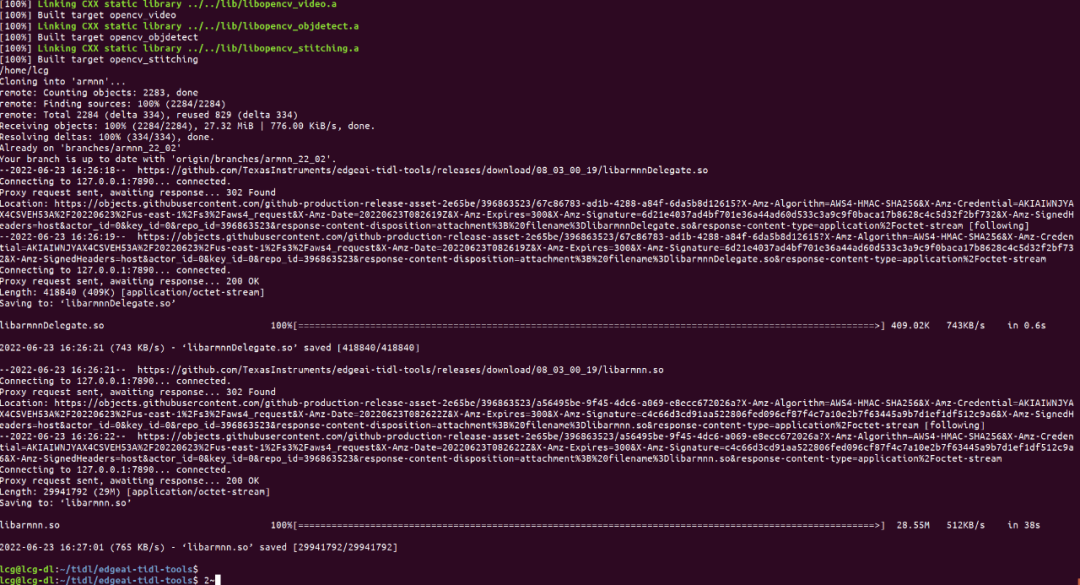
配置环境变量
在代码里面有大量使用系统环境变量的地方,需要事先将环境变量设置好


1 | export DEVICE=j7export TIDL_TOOLS_PATH="/home/lcg/tidl/edgeai-tidl-tools" |
临时修改环境比那两只需要在shell中直接执行export即可,如果需要一劳永逸,添加到~/.bahsrc中即可
2,验证环境是否可用
1 | ./scripts/run_python_examples.sh |
脚本中包含了很多验证的过程,如果哪一步骤出错,可以单独验证
如果出现这种情况
1 | ValueError: could not load library libvx_tidl_rt.so |
或者下面这种情况
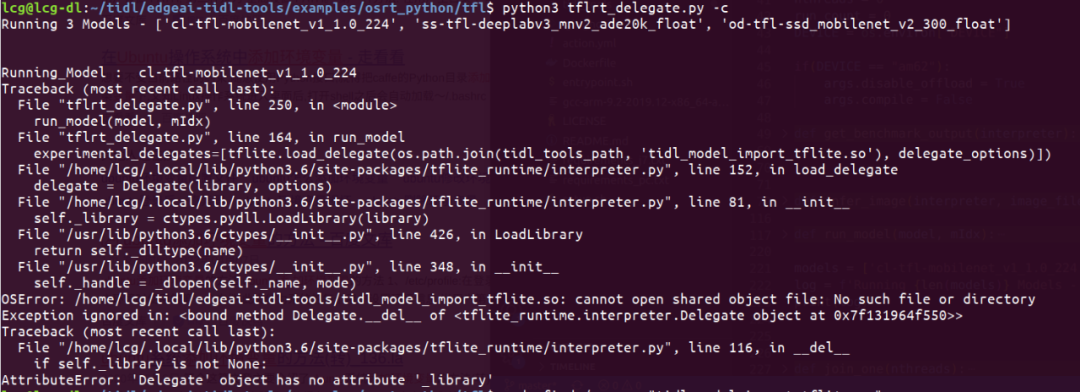
需要在当前shell终端重新运行source ./setup.sh,配置当前终端环境
1 | /home/lcg/tidl/edgeai-tidl-tools/tidl_tools/tidl_graphVisualiser.out: error while loading shared libraries: libcgraph.so.6: cannot open shared object file: No such file or directory |
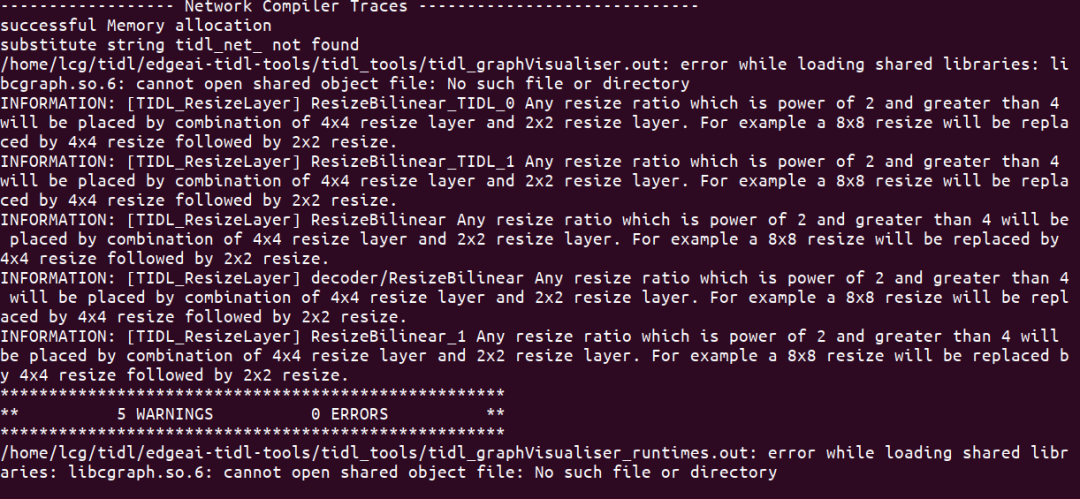
没有找到libcgraph.so库,如果安装过,则把路径添加到$ld_LIBRARY_PATH即可
如果没有安装过,则sudo apt install graphviz
使用python脚本验证example
python脚本可以同时完成模型转换和推理验证
使用如下命令生成artifacts,并生成结果图片
1 | cd examples/osrt_python/tflpython3 tflrt_delegate.py -c#具体 -c -d 参数可以参考代码 |
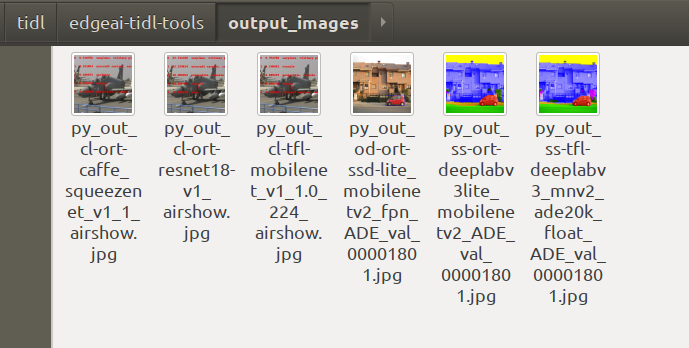
如果能生成以上结果,就说明python运行example没有问题
使用C++验证example
C++的example只能完成推理验证,不能做模型转换。所以需要使用python代码生成的artifacts来做推理生成结果
C++的API需要读取yaml文件,所以需要单独安装一个库
1 | sudo apt install libyaml-cpp-dev |
在edgaai-tidl-tools目录下创建build文件夹用来生成编译文件
1 | mkdir build && cd build |
在编译过程中,通过cmake设置参数来指定编译类型
1 | cmake-gui ../example |
•TENSORFLOW_INSTALL_DIR : defaults check at ~/tensorflow•ONNXRT_INSTALL_DIR: defaults check at ~/onnxruntime•DLR_INSTALL_DIR: defaults check at ~/neo-ai-dlr•OPENCV_INSTALL_DIR: defaults check at ~/opencv-4.1.0•ARMNN_PATH: defaults check at ~/armnn•TARGET_FS_PATH: defaults check ~/targetfs•CROSS_COMPILER_PATH: defaults check ~/gcc-arm-9.2-2019.12-x86_64-aarch64-none-linux-gnu
这里采用默认配置即可
1 | #例如你要修改opencv路径#cmake -DOPENCV_INSTALL_DIR="/home/opencv4.1" -DTARGET_CPU=arm ../examplesmake -jcd ../ |
在repo的根目录生成bin文件夹

运行example
1 | # -f 指定artifacts,由python脚本生成# -i 指定输入图像./bin/Release/ort_main -f model-artifacts/od-ort-ssd-lite_mobilenetv2_fpn -i test_data/ADE_val_00001801.jpg |

3,SOC端推理
在模型转化阶段生成的artifacts,此处就派上用场了
将文件夹拷贝到soc板,./model-artifacts,models
这里的脚本只能验证流程是否跑通,并不能得到具体的精度数据,如果需要量化评估,需要参考ti 提供的benchmark[4]
References
[1] TF-Lite: https://www.tensorflow.org/lite/guide/inference[2] TFLite Delgate API: https://www.tensorflow.org/lite/performance/delegates[3] 搭建环境: https://github.com/TexasInstruments/edgeai-tidl-tools/blob/master/README.md#setup[4] benchmark: https://github.com/TexasInstruments/edgeai-benchmark