
本文介绍MobiSys 2021年的文章《Low-latency Speculative Inference On Distributed Multi-modal Data Streams》。多模态数据流(multi-modal data streams)在在分布式传感任务中很常见,常用的场景有人物跟踪、行为识别以及音频和视频分析等。考虑到不同模态数据之间高度的异构性,不同模态的数据传输速度是不一致的,因而较慢的数据流会显著地降低整个系统的推理性能和准确率。为此,该篇文章提出推测式推理来自动调节和适应多模态数据流中传输速度不一致的问题。与已有工作阻塞式推理的有所不同,该文章会根据残缺不完整的数据,推测生成一个完整的数据,并根据此生成的数据进行推断。同时,该文章提供一个回滚机制,用以确定是否可以接受利用不完整数据得到的推理结果。当在不接受结果时,回滚机制会等到足够多的数据到达时在做推理,以保证结果的正确性。实验显示该篇文章提出的方法,与最新的六个基准工作相比,能够在保证准确率不变的情况下,7-128倍的降低推断延迟
目前物联网设备上配有大量低功耗但数据丰富的传感器(如相机、麦克风、激光雷达、高光谱成像仪和射频成像仪)。这些传感器可以提供多种大量连续的数据用以进行复杂环境下的推理。这类多模态数据流的推理可以显著地提升语音识别、健康检测、增强现实和自动驾驶等任务的准确率。尽管有这么多的好处,多模态推理面临着多个数据流之间不同步,甚至是数据缺失的问题,具体带来三个挑战:(1) 多模态数据往往是不同维度的,差别较大(比如:音频和视频),因而很难通过某个模态的数据流去恢复或创建其他缺失的数据流。(2) 需要设计一个简单高效的回滚机制,既要保证尽可能地少进行回滚,又要保证回滚本身的开销较小。(3) 多个模态数据流之间存在时间漂移问题,即很多传感器设备由于缺少时钟同步,进而造成时间戳不准的现象。
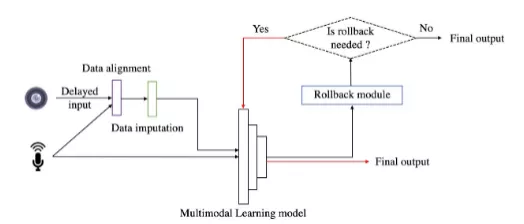
为了解决上述问题,该文作者提出了推测式推理的方法予以解决。如图1所示,具体包含三个部分:数据对齐模块、数据填补模块和回滚模块。多模态数据首先经过数据对齐模块,将不同模态间的数据时间戳对齐,然后数据填补模块会根据某个模态的数据流生成缺失模态的数据,并将生成的数据和原始的数据一并输入到多模态学习模型中。如果得到的结果是可以相信的,那么直接输出,否则回滚模块进行处理,得到最终的正确数据。接下来本文将详细展开这三部分的详细实现。
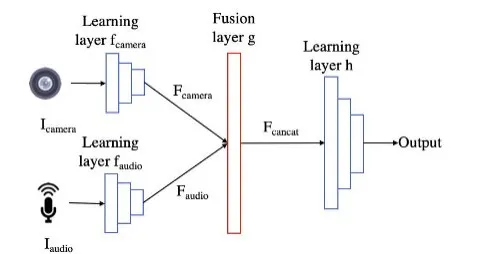
数据填补模块
该文发现,直接用某个模态的数据流去生成另外一个模态的数据是十分困难的,同时也需要大量的训练开销。为此该文调研了多模态数据进行推断的方法,如图2所示。不同模态的数据首先经过各自的特征向量提取层,得到各自的feature map,然后将这些feature map拼接在一起经过后续的处理层,得到最终的输出。基于调研结果,该文提出基于某个模态的数据流去生成另一个模态的feature map的方法,既能保证生成的feature map准确,又能保证训练和生成过程的开销比较小,具体如图3所示。该文使用生成对抗网络(GAN)进行训练,训练时设置生成器和辨别器两个部分,生成器用于生成缺失数据流的feature map,辨别器用于区分生成的feature map和真实数据生成的feature map。生成器和辨别器相互对抗最后得到一个能够生成缺失数据流feature map的模型。
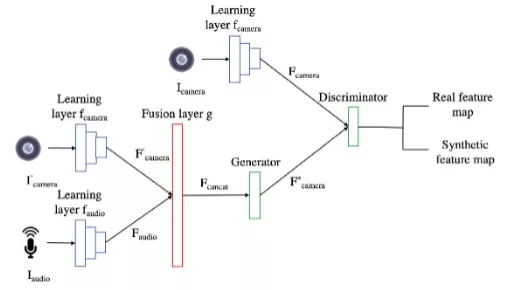
回滚模块
该文发现不同类别的数据对某个模态数据的缺失的反应是不同的,比如“under”这个词仅通过唇语就能识别,而“allegations”却很难。针对这一现象,该文对所有待识别的数据做了分类,获得了每一个类别的数据要想准确预测出正确结果所需要的最少模态数据信息。基于这个信息设置回滚模块,当推测时已有的数据大于最少模态数据信息时,就不回滚;否则反之。

数据对齐模块
该文发现,当两个模态的不同时刻的数据得到的推理结果具有最小的“距离”,那么这两个来自不同模态的时刻,实际上是一致的。图4给出了4个例子,画红圈的地方表示最小距离的时刻,也就是两个模态数据流时间偏移的距离。
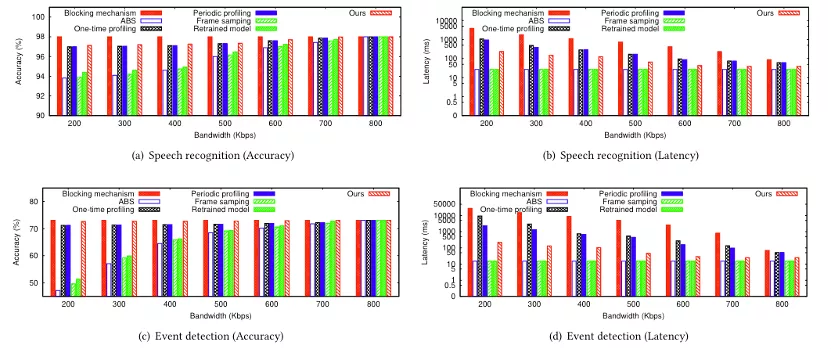
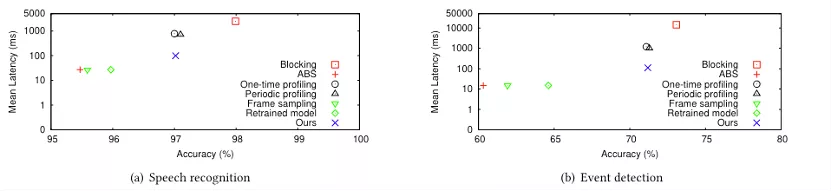
本文所提出的工作在一个带有Xeon E5-2620 v3 2.40 GHz CPU和两个GTX-1080Ti GPU的32 GB RAM边缘服务器上实现的。并与阻塞算法(Blocking mechanism)、自适应码率算法(ABS)、周期分析法(Periodic profiling)、一次分析方法(One-time profiling)和帧采样算法(frame sampling)在语音识别数据集(LRW)、事件检测数据集(AVE)和活动识别数据集(STISEN)进行了比较,对比结果如图5和6所示。在模拟Trace上显示,该文提出的方法能够降低2-128倍的延迟,并提高1%-25%的准确率。在真实Trace上显示,该文提出的方法能够在延迟上与自动码率和帧采样算法类似,但却能得到和分析与阻塞算法一样的准确率,达到了同时降低延迟,并提升准确率的目的。