随着海量数据的出现和模型参数的增多,我们必然需要更大的集群来运行模型,这样最大的好处在于把原本可能需要周级别的训练时间缩短到天级别甚至小时级别。未来的模型训练面对的都是上亿数据和上亿参数,稳定的计算能力和管理便捷的集群环境至关重要。Kubernetes 是目前应用最广泛的容器集群管理工具之一,它可以为对分布式TensorFlow 的监控、调度等生命周期管理提供所需的保障。
分布式TensorFlow 在Kubernetes 中的运行
本节介绍在Kubernetes 中运行分布式TensorFlow 的方法。首先学习如何部署Kubernetes 环境,接着在搭建好的环境中运行分布式TensorFlow,并用MNIST 来训练。
部署及运行
首先需要先安装Kubernetes。
用Minikube 来创建本地Kubernetes 集群。安装Minikube 需要预先安装VirtualBox 虚拟机,可以从官网上直接下载安装,注意选择对应的操作系统版本即可。 
Minikube 用Go 语言编写,发布形式是一个独立的二进制文件,所以只需要下载下来,然后放在对应的位置即可。因此安装Minikube,只需要一条命令:
1
2
3
| curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.14.0/
minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
|
Kubernetes 提供了一个客户端kubectl,可直接通过kubectl 以命令行的方式与集群交互。
安装kubectl 的方法如下:
1
| curl -Lo kubectl http://storage.googleapis.com/kubernetes-release/release/v1.5.1/bin/darwin/amd64/kubectl && chmod +x kubectl && sudo mv kubectl /usr/local/bin/
|
下面在Minikube 中启动 Kubernetes 集群,如图所示。

可以观察到VirtualBox 中也启动了相应的虚拟机,如图所示。
采用Docker Hub上的最新镜像tensorflow/tensorflow(基于TensorFlow 的1.0 版本)。
首先,配置参数服务器的部署(deployment)文件,命名为tf-ps-deployment.json。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| {
"apiVersion": "extensions/v1beta1",
"kind": "Deployment",
"metadata": {
"name": "tensorflow-ps2"
},
"spec": {
"replicas": 2,
"template": {
"metadata": {
"labels": {
"name": "tensorflow-ps2",
"role": "ps"
}
},
"spec": {
"containers": [
{
"name": "ps",
"image": "tensorflow/tensorflow",
"ports": [
{
"containerPort": 2222
}
]
}
]
}
}
}
}
|
配置参数服务器的服务(Service)文件,命名为tf-ps-service.json,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| {
"apiVersion": "v1",
"kind": "Service",
"spec": {
"ports": [
{
"port": 2222,
"targetPort": 2222
}
],
"selector": {
"name": "tensorflow-ps2"
}
},
"metadata": {
"labels": {
"name": "tensorflow",
"role": "service"
},
"name": "tensorflow-ps2-service"
}
}
|
配置计算服务器的部署文件,命名为tf-worker-deployment.json,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| {
"apiVersion": "extensions/v1beta1",
"kind": "Deployment",
"metadata": {
"name": "tensorflow-worker2"
},
"spec": {
"replicas": 2,
"template": {
"metadata": {
"labels": {
"name": "tensorflow-worker2",
"role": "worker"
}
},
"spec": {
"containers": [
{
"name": "worker",
"image": "tensorflow/tensorflow",
"ports": [
{
"containerPort": 2222
}
]
}
]
}
}
}
}
|
配置计算服务器的服务文件,命名为tf-worker-service.json,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| {
"apiVersion": "v1",
"kind": "Service",
"spec": {
"ports": [
{
"port": 2222,
"targetPort": 2222
}
],
"selector": {
"name": "tensorflow-worker2"
}
},
"metadata": {
"labels": {
"name": "tensorflow-worker2",
"role": "service"
},
"name": "tensorflow-wk2-service"
}
}
|
执行以下命令:
1
2
3
4
5
6
7
| kubectl create -f tf-ps-deployment.json
kubectl create -f tf-ps-service.json
kubectl create -f tf-worker-deployment.json
kubectl create -f tf-worker-service.json
|
分别输出以下结果:
1
2
3
4
5
6
7
| deployment "tensorflow-ps2" created
service " tensorflow-ps2-service" created
deployment "tensorflow-worker2" created
service "tensorflow-wk2-service" created
|
稍等片刻,运行kubectl get pod,可以看到参数服务器和计算服务器全部创建完成

下面我们进入每个服务器(Pod)中,部署好需要运行的mnist_replica.py 文件。
首先查看以下2 台ps_host 的 IP 地址
然后查看2 台worker_host 的IP 地址
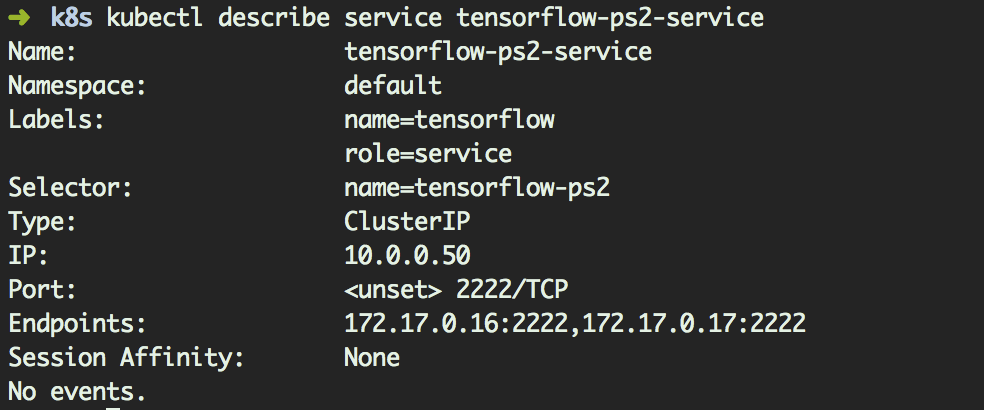
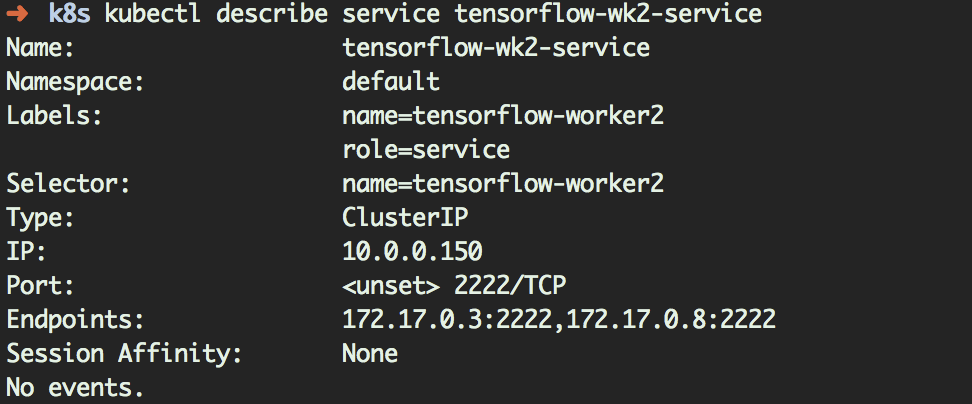
打开4 个终端,分别进入4 个Pod 当中,命令如下:
1
2
3
4
5
6
7
| kubectl exec -ti tensorflow-ps2-3073558082-3b08h /bin/bash
kubectl exec -ti tensorflow-ps2-3073558082-4x3j2 /bin/bash
kubectl exec -ti tensorflow-worker2-3070479207-k6z8f /bin/bash
kubectl exec -ti tensorflow-worker2-3070479207-6hvsk /bin/bash
|
通过下面的方式将mnist_replica.py 分别部署到4 个Pod 中,如下:
1
2
3
| curl https://raw.githubusercontent.com/tensorflow/tensorflow/master/
tensorflow/tools/dist_test/python/mnist_replica.py -o mnist_replica.py
|
在参数服务器的两个容器中分别执行:
1
2
3
4
5
6
7
| python mnist_replica.py --ps_hosts=172.17.0.16:2222,172.17.0.17:2222 --worker_
hosts=172.17.0.3:2222,172.17.0.8:2222 --job_name="ps" --task_index=0
python mnist_replica.py --ps_hosts=172.17.0.16:2222,172.17.0.17:2222 --worker_
hosts=172.17.0.3:2222,172.17.0.8:2222 --job_name="ps" --task_index=1
|
在计算服务器的两个容器中分别执行:
1
2
3
4
5
6
7
| python mnist_replica.py --ps_hosts=172.17.0.16:2222,172.17.0.17:2222 --worker_
hosts=172.17.0.3:2222,172.17.0.8:2222 --job_name="worker" --task_index=0
python mnist_replica.py --ps_hosts=172.17.0.16:2222,172.17.0.17:2222 --worker_
hosts=172.17.0.3:2222,172.17.0.8:2222 --job_name="worker" --task_index=1
|
执行输出与14.6 节的输出类似。一共执行200 次迭代,工作节点1(172.17.0.3:2222)执行了144 次迭代,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| job name = worker
task index = 0
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:200] Initialize
GrpcChannelCache for job ps -> {0 -> localhost:2222}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:200] Initialize GrpcChannel
Cache for job worker -> {0 -> localhost:2223, 1 -> localhost:2224}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:217] Started server
with target: grpc://localhost:2223
Worker 0: Initializing session...
I tensorflow/core/distributed_runtime/master_session.cc:994] Start master session
0d791a02977e5701 with config:
device_filters: "/job:ps"
device_filters: "/job:worker/task:0"
allow_soft_placement: true
Worker 0: Session initialization complete.
Training begins @ 1483516057.489495
1483516057.518419: Worker 0: training step 1 done (global step: 0)
1483516057.541053: Worker 0: training step 2 done (global step: 1)
1483516057.569677: Worker 0: training step 3 done (global step: 2)
1483516057.584578: Worker 0: training step 4 done (global step: 3)
1483516057.646970: Worker 0: training step 5 done (global step: 4)
\# ……中间略去
1483516059.286596: Worker 0: training step 141 done (global step: 197)
1483516059.291600: Worker 0: training step 142 done (global step: 198)
1483516059.297347: Worker 0: training step 143 done (global step: 199)
1483516059.303738: Worker 0: training step 144 done (global step: 200)
Training ends @ 1483516059.303808
Training elapsed time: 1.614513 s
After 200 training step(s), validation cross entropy = 1235.56
|
工作节点2(172.17.0.8:2222)执行了56 次迭代,输出如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| job name = worker
task index = 1
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:200] Initialize GrpcChannel
Cache for job ps -> {0 -> localhost:2222}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:200] Initialize GrpcChannel
Cache for job worker -> {0 -> localhost:2223, 1 -> localhost:2224}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:217] Started server
with target: grpc://localhost:2224
Worker 1: Waiting for session to be initialized...
I tensorflow/core/distributed_runtime/master_session.cc:994] Start master session
92e671f3dd1ffd05 with config:
device_filters: "/job:ps"
device_filters: "/job:worker/task:1"
allow_soft_placement: true
Worker 1: Session initialization complete.
Training begins @ 1483516058.803010
1483516058.832164: Worker 1: training step 1 done (global step: 121)
1483516058.844464: Worker 1: training step 2 done (global step: 123)
1483516058.860988: Worker 1: training step 3 done (global step: 126)
1483516058.873543: Worker 1: training step 4 done (global step: 128)
1483516058.884758: Worker 1: training step 5 done (global step: 130)
\# ……中间略去
1483516059.152332: Worker 1: training step 52 done (global step: 176)
1483516059.167606: Worker 1: training step 53 done (global step: 178)
1483516059.177215: Worker 1: training step 54 done (global step: 180)
1483516059.301384: Worker 1: training step 55 done (global step: 182)
1483516059.309557: Worker 1: training step 56 done (global step: 202)
Training ends @ 1483516059.309638
Training elapsed time: 0.536126 s
After 200 training step(s), validation cross entropy = 1235.56
|
在这个例子中,更好的方式是把需要执行的源代码以及训练数据和测试数据放在持久卷(persistent volume)中,在多个Pod 间实现共享,从而避免在每一个Pod 中分别部署。对应TensorFlow 的GPU 的Docker 集群部署,Nvidia 官方提供了nvidia-docker 的方式,原理主要是利用宿主机上的GPU 设备,将它映射到容器中。更多与部署相关的内容可以参考https://github.com/NVIDIA/nvidia-docker。
其他应用
训练好模型之后可以将它打包制作成环境独立的镜像,这样能够极大地方便测试人员部署一致的环境,也便于对不同版本的模型做标记、比较不同模型的准确率,从整体上降低测试、部署上线等的工作复杂性,具有很大的优势。
小结
将Kubernete 与TensorFlow 结合,借助Kubernetes 提供的稳定计算环境,对TensorFlow 集
群进行便捷的管理,降低了搭建大规模深度学习平台的难度,这也是社区非常推崇的部署方案。
本章主要讲述了用Kubernetes 管理TensorFlow 集群的方法,以及在Kubernetes 上部署分布式
TensorFlow 的方式,最后采用MNIST 的分布式例子进行了实践。
