
DARTS是可微分网络架构搜索,而本文将要解读的PC-DARTS是DARTS的扩展。DARTS方法速度快,但是由于它需要训练一个超网来寻找最优结构,需要消耗大量的内存和计算资源。因此论文作者提出了Partially-ConnectedDARTS,即部分通道连接的DARTS方法,通过对super-net进行一小部分的采样,能够减少网络搜索过程中计算的内存占用。但是由于通过在通道子集上执行运算搜索,而其他部分不变,这可能导致挑选超大网络边时出现不一致,为了解决这个问题,作者提出了边正则化,在搜索中添加边级别的超参数集合,来减少搜索的不确定性。

引言
DARTS把运算操作进行连续松弛,可以让网络的超参数搜索可微,进而达到端对端的网络搜索。但是由于在一个很大的超网上进行搜索,导致它的搜索空间有大量的冗余,使得计算量和内存占用很大。作者为了减少内存和计算量,采用这样的思路:不用把全部通道都送入运算选择中,而是对通道子集进行随机采样进行运算,其他的通道直接通过。但是这种思路带来了一种问题:由于采样的随机性,网络连接的选择可能是不稳定的。由此作者又引入了边正则化(edgenormalization)进行稳定,添加一个额外的边选择超参数集合。同时得益于部分通道连接的策略,选择1/K的通道可以减少K倍内存,那么就可以增大K倍的batchsize,不仅可以加速K倍,还可以稳定搜索。
方法
DARTS把网络的搜索拆分为L个cell,每个cell为N个节点的有向无环边,每个节点是一个网络层。Cell的类型有两种:ReductionCell和NormalCell,在整个超网中共享。
一般网络的每一层代表着一种操作,这个操作可能是卷积、池化、激活等函数,但在超网络SuperNet中,每一层网络是由多种运算组合起来的,每一种运算对应一个系数$\alpha$,,混合运算的加权公式如下:$f_{i, j}\left(\mathbf{x}{i}\right)=\sum{o \in \mathcal{O}} \frac{\exp \left{\alpha_{i, j}^{o}\right}}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left{\alpha_{i, j}^{o^{\prime}}\right}} \cdot o\left(\mathbf{x}_{i}\right)$
Partial Channel Connections
DARTS的问题是需要大量内存,为了调节$|\theta|$个运算,需要把每个运算的结果存储起来,需要使用$|\theta|$倍的内存,为了能存下必须降低batchsize大小,这就降低了速度。而本文提出了partially-connectedDARTS方法,简称为PC-DARTS,方法如图1所示。该方法将网络提取的特征在通道维度上进行了1/K采样,只对采样后的通道进行处理,然后将这些特征与剩余的特征进行拼接(concat)。为了减少由采样带来的不确定性,作者又提出了边正则化,添加了边级别的超参数$\beta$
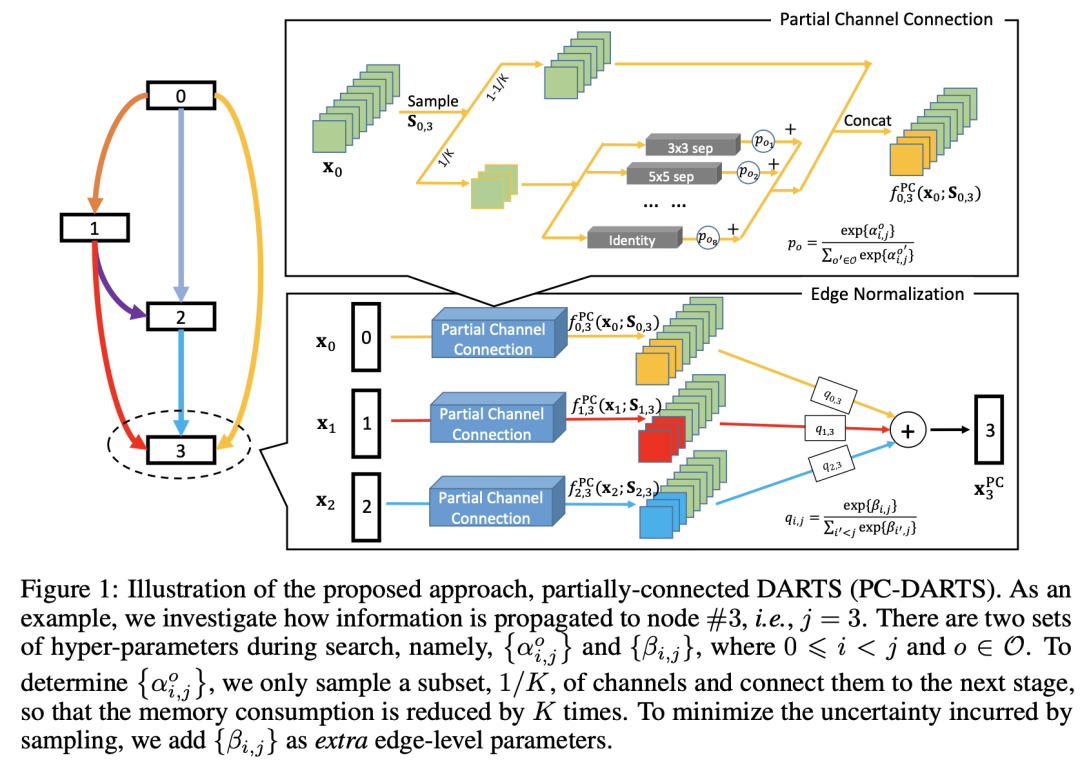
PC-DARTS的运算加权公式为:$f_{i, j}^{\mathrm{PC}}\left(\mathbf{x}{i} ; \mathbf{S}{i, j}\right)=\sum_{o \in \mathcal{O}} \frac{\exp \left{\alpha_{i, j}^{o}\right}}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left{\alpha_{i, j}^{o^{\prime}}\right}} \cdot o\left(\mathbf{S}{i, j} * \mathbf{x}{i}\right)+\left(1-\mathbf{S}{i, j}\right) * \mathbf{x}{i}$
其中$S_{i,j}$为通道采样mask,标为1的通道直接作为输出。我们随机采样1/K个通道,其中这个K我们作为超参数用来平衡速度和准确率。挑选出通道的1/K可以减少K倍的计算量,还可以有更多的样本来采样,这对于网络搜索尤为重要。
Edge Normalization
上一节中对通道进行随机采样的好处是能减少所选操作的偏置,即对于边(i,j),给定$x_i$,使用两组超参数${\alpha^{o}{i,j}}$和$${\alpha^{o’}{i,j}}$$的差距就减小了。但是它削弱了无权重运算(如跳层连接,最大池化)的优势。在早期,搜索算法更喜欢无权重的运算,因为这些运算没有参数,能够得到输出一致的结果。但是对于有权重的运算,优化过程中会出现不一致的情况。这样无权重的运算会占据很大的比重,后续即使有权重的运算优化的很好,也无法超过它们。这种现象在代理输入比较困难的时候尤其严重,这也导致DARTS在ImageNet上效果不好。
为此提出了边正则化来抑制该现象。边正则化为基本单元中的第i层网络的每个输入分配了一个$\beta$参数,公式表示如下:$\mathbf{x}{j}^{\mathrm{PC}}=\sum{i<j} \frac{\exp \left{\beta_{i, j}\right}}{\sum_{i^{\prime}<j} \exp \left{\beta_{i^{\prime}, j}\right}} \cdot f_{i, j}\left(\mathbf{x}_{i}\right)$
实验
作者在两个常用的公共数据集CIFAR-10和ImageNet进行了实验。
CIFAR-10实验结果
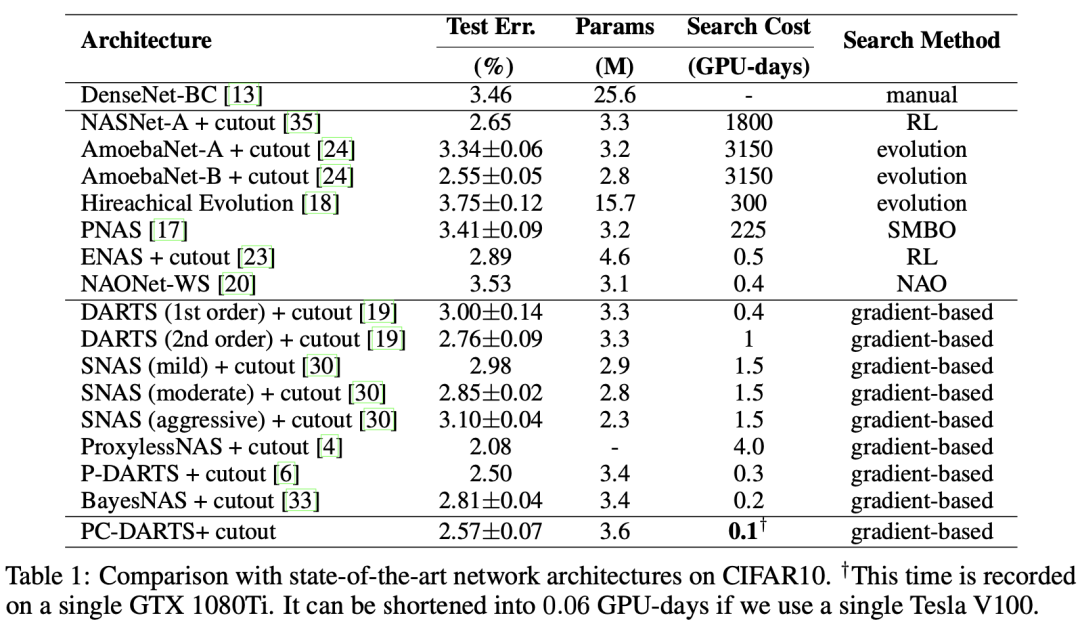
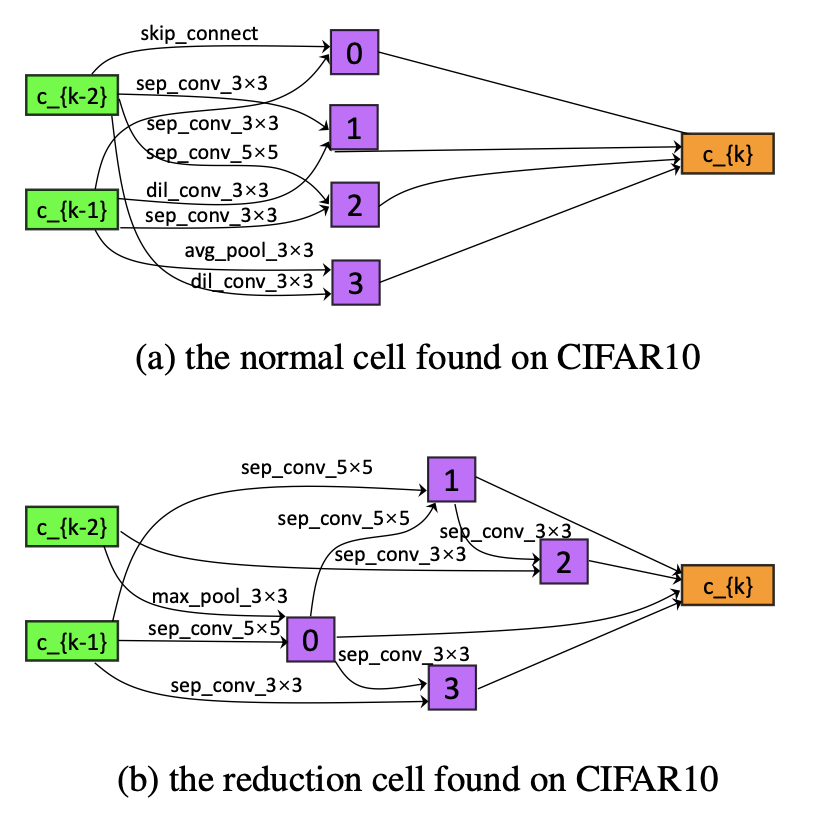
CIFAR-10上的实验结果如图2所示。在搜索过程中,网络由8个cell堆叠组成(包含6个normalcells和2个reductioncells),并且每个cell由6个节点构成,normalcell和reductioncell结果如图2所示。
CIFAR-10上,选用K=4,即只有1/4的通道被采样,因此搜索期间的batchsize增加到256。训练时,SuperNet首先预热15个epochs(即固定架构超参数,只更新网络参数),使用带动量的SGD进行网络参数的优化,使用Adam优化器来对超参数${\alpha^{o}{i,j}}$和$\beta{i,j}$进行更新。
从表中可以看到,使用PC-DARTS方法,仅需0.1GPU天,错误率就可以达到2.57%,搜索时间和准确率都超过了baseline方法DARTS。在比较的方法中,PC-DARTS是错误率小于3%的方法中速度最快的。
ImgaeNet上的实验结果
在ImageNet上的实验结果以及和SOTA方法的比较如表2所示。作者对用于CIFAR-10上的网络结构进行了小修改以适用于ImageNet。为了减小搜索时间,作者分别从ImageNet上随机采样了两个子集,采样率分别为10%和2.5%,前者用于训练网络参数权重,后者用于更新架构超参数。
由于在ImageNet进行搜索比CIFAR-10更难,为了保留更多的信息,选取K=2,即通道采样率为1/2,是CIFAR-10的两倍。仍然训练50个epochs,但是前35个epochs固定架构超参数,其他训练设置基本和CIFAR-10上的一致。
在ImageNet上的结果如表2所示,在ImageNet上的实验结果,Top-1和Top-5准确率可以达到24.2%和7.3%,是比较的方法中效果最好的,也证明了本方法在减少内存消耗上是有效的。
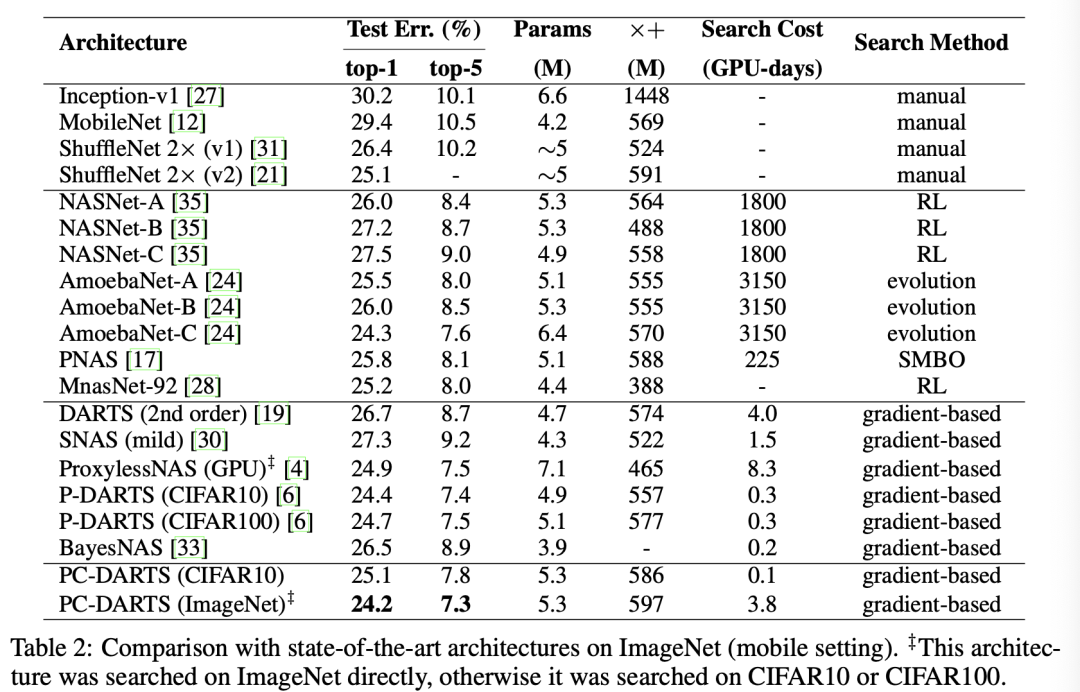
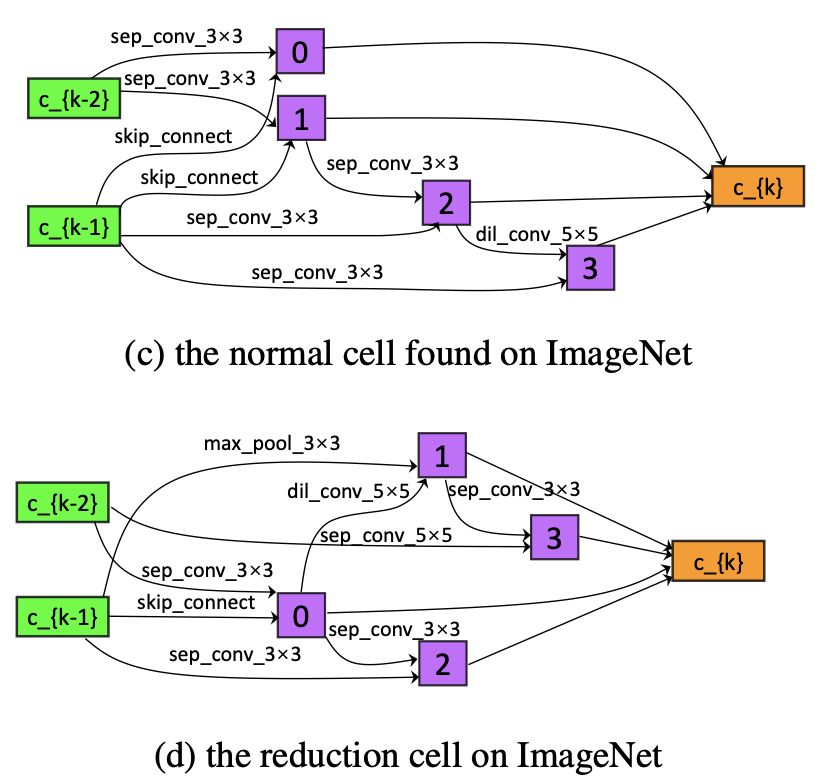
在ImageNet上搜索得到的normalcell和reductioncell如下图所示。
消融实验
1. 不同采样率的结果
K是用来控制通道的采样率的一个超参数,在讨论K对实验结果的影响之前,要先明确这么一个信息:增加采样率(即使用一个更小的K值)能使得更精确的信息被传播;而对通道的更小一部分进行采样,会造成更大的正则化,可能会引起过拟合。为了研究K的影响,作者在CIFAR-10上实验了4种K值对性能的影响,分别为1/1,1/2,1/4和1/8,实验结果如图4所示。从图中可以看出来采样率在1/4时的效果最好,准确率最高,搜索速度最快。使用1/8的采样率,尽管会进一步减少搜索时间,但是会产生严重的性能下降。 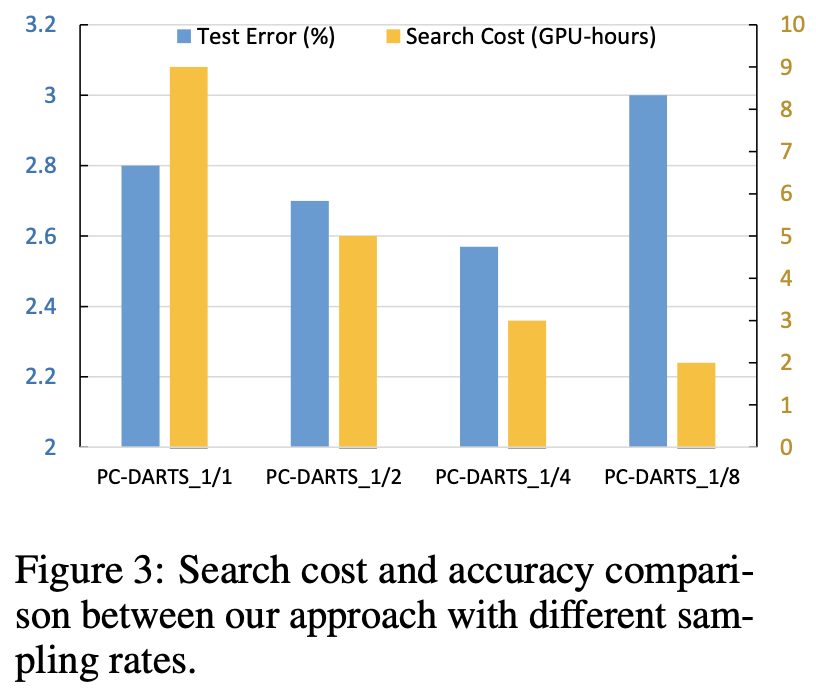
2. PC-DARTS不同组件的作用
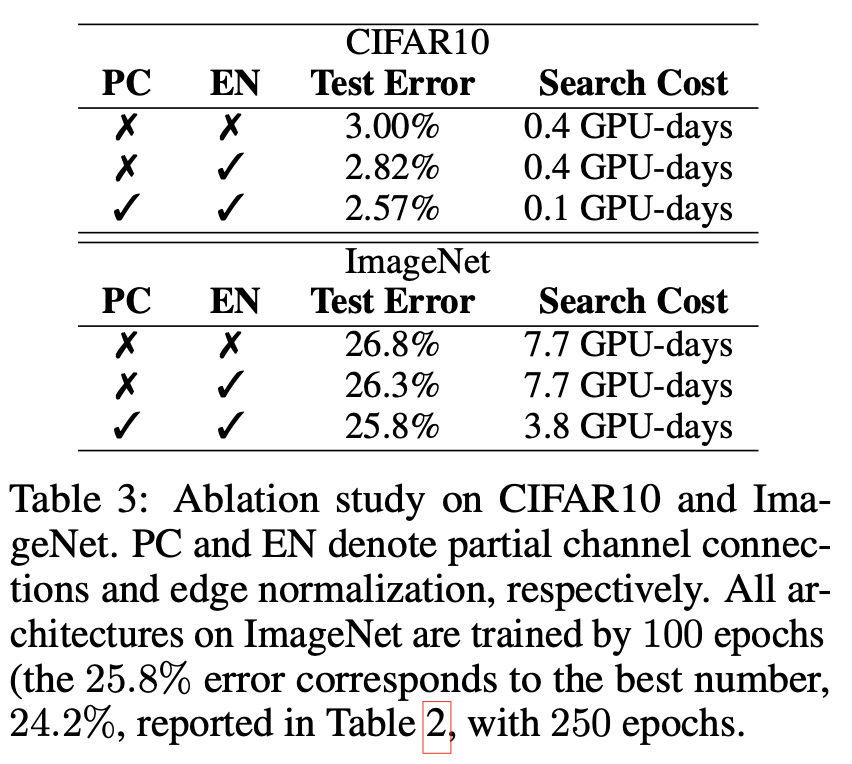
作者又探讨PC-DARTS中的partialchannel connection(表中简称为PC)和edgenormalization(表中简称为EN)的作用,结果如表3所示。从表中可以很明显看到,EN及时在通道是全部连接的情况下,也能带来正则化的效果。同时,edgenormalization和partialchannel connection一起使用,可以提供更进一步的改进效果。而不使用edgenormalization,则网络参数的数量和精确度都会受到影响。
结论
本篇论文提出了一个简单但却有效的PC-DARTS(partially-connecteddifferentiable architecturesearch)方法,它的核心思想是随机采样一部分通道用于运算搜索,这样能更有效的利用内存,可以使用更大的batchsize获得更高的稳定性。另一个贡献是提出了边标准化(edgenormalization)来稳定搜索的过程,这是个轻量化的模块,基本不需要太多的计算量。此方法在CIFAR-10上完整搜索只需要0.1GPU天,在Imagenet上搜索需要3.8GPU天。