
整理了一些最近的object detection算法
忽然发现。。。。
这是要开启NAS时代的神仙打架了嘛/facepalm不过讲真…Google这些nas论文,计算量贼大,要卡要数据的啊……复现起来不是一点两点困难
“我是FAIR时代的残党!新时代没有能载我的模型!”(说白了就是没卡。。。。)
为了紧跟时代潮流,了解一下AutoML去看了一下《Neural Architecture Search: A Survey》这篇综述
序
深度学习模型在很多任务上都取得了不错的效果,但调参对于深度模型来说是一项非常苦难的事情,众多的超参数和网络结构参数会产生爆炸性的组合,常规的 random search 和 grid search 效率非常低,为此人们想出了自动搜索神经网络架构(Neural Architecture Search)。一方面,自动神经网络架构搜索可以遍历架构找到性能最优的架构,另一方面自动神经网络架构搜索还可以打破人类思维的局限性找到人类所想不到的架构组织方式。
本文从网络架构搜索的三个方面进行了分类综述,包括:
搜索空间
搜索策略
评价预估
搜索空间
搜索空间定义了NAS方法原则上可能发现的神经体系结构即优化问题的变量。深度学习模型的性能是由参数来控制和决定的,所以只需要对复杂模型的架构参数和对应的超参数进行优化即可。
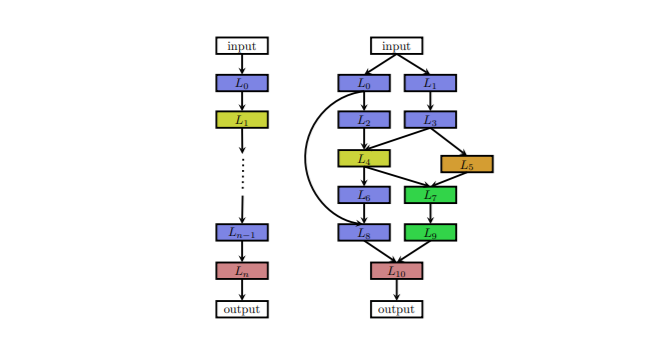
上图是两种不同的架构空间,图片中每个节点表示神经网络中的一层,例如卷积层,池化层,不同的层由不同的颜色标注。箭头描述了数据的流向。
左侧的图像是一个链式结构空间的组块,这种结构相当于一个 N 层的序列,每一层有几种可选的算子,比如卷积、池化等,每种算子包括一些超参数,比如卷积尺寸、卷积步长等。
右侧的图像是一个拥有多分支和跳远链接的搜索空间的组块。
链式结构神经网络通过层数N,层间操作,卷积核大小步幅等超参对搜索空间进行参数化,注意:搜索空间的参数不是固定长度的,而是条件空间。
分支结构用$g_{i}\left(L_{i-1}^{o u t}, \ldots, L_{0}^{o u t}\right)$来表示第$i$层的输入,则分支结构的特殊情况分为:
- 链结构网络
$$
g_{i}\left(L_{i-1}^{o u t}, \ldots, L_{0}^{o u t}\right)=L_{i-1}^{o u t}
$$
- 残差网络
$$
\left(g_{i}\left(L_{i-1}^{o u t}, \ldots, L_{0}^{o u t}\right)=L_{i-1}^{o u t}+L_{j}^{o u t}, j<i-1\right.
$$
- Densenet
$$
g_{i}\left(L_{i-1}^{o u t}, \ldots, L_{0}^{o u t}\right)=\operatorname{concat}\left(L_{i-1}^{o u t}, \ldots, L_{0}^{o u t}\right)
$$
通过以上方式分别搜索这样的组块,这样的组块又被优化为保留输入维度的normal cells和减小空间维度的reduction cell(通过使stride=2)。最后通过预定义的方式堆叠这些组块构建最终的体系结构。
搜索策略
搜索策略详细说明了如何探索搜索空间,它一方面希望快速找到性能良好的架构,另一方面,也要避免过早收敛到次优架构的区域。搜索策略包括随机搜索(RS),贝叶斯优化(BO),进化方法,强化学习(RL)和基于梯度的方法。
强化学习方法,将神经体系结构的产生视为代理动作,将搜索空间视为动作空间,将体系结构的性能评估视为奖励,不同的RL方法在表示代理策略和如何优化策略方面有所不同。Neural architecture search with reinforcement learning使用递归神经网络(RNN)策略顺序采样字符串,进而对神经体系架构进行编码,他们最初使用REINFORCE policy gradient 算法训练了该网络,但是后来的工作中(Learning transferable architecturs for scalable image recognition / Proximal policy optimization algorithms)使用了Proximal Policy Optimization;Designing neural network architectures using reinforcement learning中使用Q-learning来训练一种可依次选择层的类型和相应超参的策略。
这些方法的一个替代观点是顺序决策过程,策略采样动作顺序生成架构,环境的状态包括目前采样的动作,并且只有在最后一个动作完成后后才能获得奖励。但是,过程中没有与环境发生互动(没有观察到外部状态,也没有中间奖励),因此将体系结构采样过程解释为单个动作的顺序生成更为直观,Efficient architecture search by network transformation提出了一种相关的方法,在他们的方法中,状态是当前(经过部分训练的)架构,奖励是对该架构性能的评估,而动作对应于保留功能的突变应用,随后是网络的训练阶段,为了处理可变长度的网络体系结构,他们使用双向LSTM将体系结构编码为固定长度的表示形式,基于此编码标识,动作网络决定采样的动作,这两个组成部分的组合构成了策略,该策略使用REINFORCE policy gradient 算法进行了端到端的训练。
进化方法用进化算法优化神经架构,第一个用此方法的可以追溯到30年前用遗传算法提出架构,用反向传播优化权重。自那以后,很多神经进化算法用遗传算法同时优化神经架构和和权重,然而,当扩展到具有数百万权重的当代神经体系结构以进行监督学习任务时,基于SGD的权重优化方法胜过进化的方法。所以后来人们使用基于梯度的方法优化权重,仅仅使用进化算法优化神经架构。进化算法进化出大量模型,即一组(可能训练有素的)网络;在每个进化步骤中,至少要采样种群中的一个模型,并作为父代通过对其应用突变来生成后代。在NAS的上下文中,变异是本地操作,例如添加或删除层,更改层的超参数,添加跳远连接以及更改训练超参数。在训练后代之后,评估它们的适应度(例如,在验证集中的表现)并将其添加到种群中。
神经进化方法在采样父母,更新种群和产生后代的方式上有所不同。采样父母:锦标赛选择、使用反密度从多目标Pareto前沿对父母进行采样。更新种群:去除最差的个人、去除最老的个体、不移除个人。产生后代:随机初始化子网络、Lamarckian inheritance:知识(以学习的权重的形式)通过使用网络态射从父网络传递到子网络、让后代继承不受其突变影响的父代所有参数。
Aging Evolution for Image Classifier Architecture Search比较了RL,evolution和random search方法,RL和进化在最终测试准确性方面表现均相当好,进化在任何时候都有更好的性能,并且找到更小的模型。在他们的实验中,这两种方法始终比RS表现更好,但幅度很小。
贝叶斯优化方法是最流行的超参数优化方法之一,但由于典型的BO工具箱基于高斯过程和专注于低维连续优化问题。Kernels for bayesian optimization in conditional parameter space和Neural architecture search with bayesian optimisation and optimal transport派生了用于架构搜索空间的内核函数,以便使用基于GP的经典BO方法。另外、一些作品使用基于树的模型,以达到在各种问题上有效地搜索高维条件空间并实现最先进的性能,共同优化神经体系结构及其超参数。尽管缺乏全面的比较,但初步证据表明这些方法也可以胜过进化算法。
Automatically Designing and Training Deep Architectures和Finding Competitive Network Architectures Within a Day Using UCT利用其搜索空间的树结构并使用了蒙特卡洛树搜索。Simple And Efficient Architecture Search for Convolutional Neural Networks提出了一种简单但性能良好的爬山算法,该算法通过贪婪地朝性能更好的架构的方向移动而发现高质量的架构,而无需更复杂的探索机制。上述方法采用离散搜索空间。DARTS提出了continuous relaxation来直接基于梯度优化operation的权重。SNAS,ProxylessNAS没有优化可能操作的权重α,而是建议在可能的操作上优化参数化分布。Differentiable neural network architecture search以及Ahmed和Maskconnect: Connextivity learning by gradient descent还采用了基于梯度的神经体系结构优化,但是分别专注于优化层超参数或连接模式。