
YOLO算法简介
YOLO十分简单,一个网络同时对多个物体进行分类和定位,没有proposal的概念,是one-stage实时检测网络的里程碑,标准版在TitanX达到45 fps,快速版达到150fps,但精度不及当时的SOTA网络
YOLO算法使用深度神经网络进行对象的位置检测以及分类,主要的特点是速度够快,而且准确率也很高,采用直接预测目标对象的边界框的方法,将候选区和对象识别这两个阶段合二为一。
Yolo算法不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想,而YOLOv3算法再以往的结构上做出了改进,增加了多尺度检测,以及更深的网络结构darknet53,这是比较主要的改进,还有某些细节上的变动。
Unified Detection
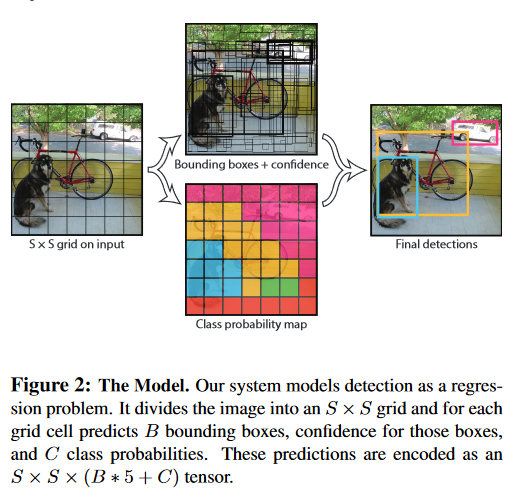
将输入分为S*S的格子,如果GT的中心点在格子中,则格子负责该GT的预测:
对于PASCAL VOC数据集来说,设定s=7如图所示,分为7*7个小格子,每个格子预测两个bounding box。
如果一个目标的中心落入一个网格单元中,该网格单元负责检测该目标。
对每一个切割的小单元格预测(置信度,边界框的位置),每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度)
置信度定义为是否存在目标与iou值的乘积,置信度可以反应格子是否包含物体以及包含物体的概率,无物体则为0,有则为IOU
$\text { Confidence } = \operatorname { Pr } ( \text { Object } ) * \text { IOU } _ { \text {pred } } ^ { \text {truth } }$
还要得到分类的概率结果;20个分类每个类别的概率。在测试时,将单独的bbox概率乘以类的条件概率得到最终类别的概率,综合了类别和位置的准确率
Network Design
YOLO采用单个的卷积神经网络进行预测,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量 。 步骤如下:
(1)骨干网络前20层接average-pooling层和全连接层进行ImageNet预训练,检测网络训练将输入从224×224增加到448×448
(2)在图像 上运行单个卷积网络
(3)由模型的置信度对所得到的检测进行阈值处理
首先,YOLO速度非常快。由于我们将检测视为回归问题,所以不需要复杂的流程。测试时在一张新图像 上简单的运行我们的神经网络来预测检测
其次,YOLO在进行预测时,会对图像进行全面地推理。与基于滑动窗口和区域提出的技术不同,YOLO在训练期间和测试时会看到整个图像,所以它隐式地编码了
关于类的上下文信息以及它们的外观。快速R-CNN是一种顶级的检测方法,但是它看不到更大的上下文信息,所以在图像中会将背景块误检为目标。与快速R-CNN相比,YOLO的背景误检数量少了一半
然后,由于YOLO具有高度泛化能力,因此在应用于新领域或碰到意外的输入时不太可能出故障。
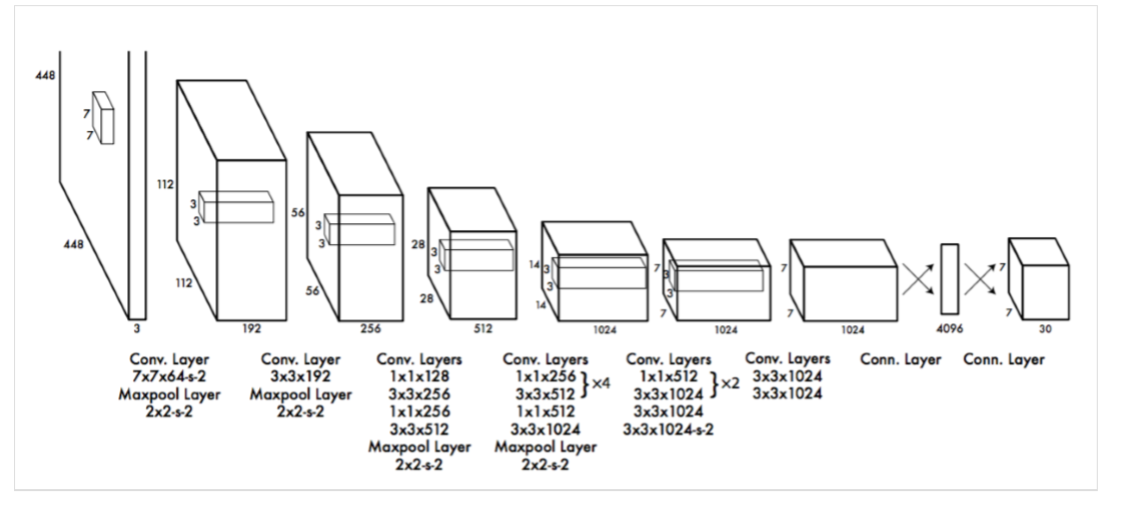
所使用的卷积结构如图所示:受到GoogLeNet图像分类模型的启发。网络有24个卷积层,后面是2个全连接层,最后输出层用线性函数做激活函数,其它层激活函数都是Leaky ReLU。
我们 只使用1×1降维层,后面是3×3卷积层,
Training
最后一层使用ReLU,其它层使用leaky ReLU
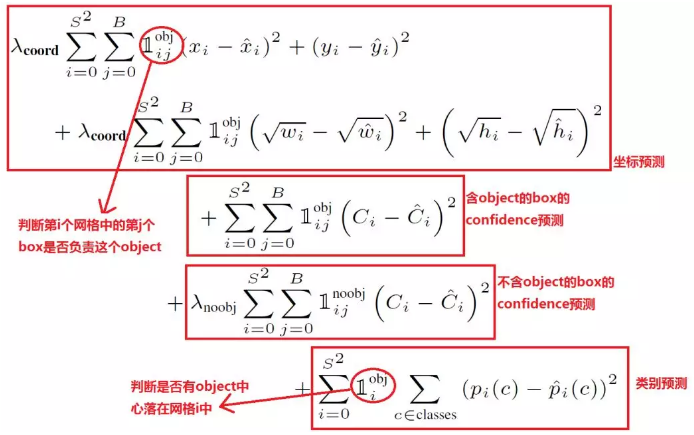
YOLO的损失函数定义如下:
$\begin{array} { c } \lambda _ { \text {coord } } \sum _ { i = 0 } ^ { S ^ { 2 } } \sum _ { j = 0 } ^ { B } \mathbb { 1 } _ { i j } ^ { \text {obj } } \left[ \left( x _ { i } - \hat { x } _ { i } \right) ^ { 2 } + \left( y _ { i } - \hat { y } _ { i } \right) ^ { 2 } \right] \ \quad + \lambda _ { \text {coord } } \sum _ { i = 0 } ^ { S ^ { 2 } } \sum _ { j = 0 } ^ { B } \mathbb { 1 } _ { i j } ^ { \text {obj } } \left[ ( \sqrt { w _ { i } } - \sqrt { \hat { w } _ { i } } ) ^ { 2 } + ( \sqrt { h _ { i } } - \sqrt { \hat { h } _ { i } } ) ^ { 2 } \right] \end{array}$
$\begin{array} { l } \quad + \sum _ { i = 0 } ^ { S ^ { 2 } } \sum _ { j = 0 } ^ { B } 1 _ { i j } ^ { \mathrm { obj } } \left( C _ { i } - \hat { C } _ { i } \right) ^ { 2 } \ + \lambda _ { \mathrm { nobbj } } \sum _ { i = 0 } ^ { S ^ { 2 } } \sum _ { j = 0 } ^ { B } 1 _ { i j } ^ { \mathrm { noobj } } \left( C _ { i } - \hat { C } _ { i } \right) ^ { 2 } \end{array}$
$+ \sum _ { i = 0 } ^ { S ^ { 2 } } \mathbb { 1 } _ { i } ^ { \mathrm { obj } } \sum _ { c \in \text { classes } } \left( p _ { i } ( c ) - \hat { p } _ { i } ( c ) \right) ^ { 2 }$
损失函数如上图,一个GT只对应一个bounding box。由于训练时非目标很多,定位的训练样本较少,所以使用权重$\begin{array} { c } \lambda _ { \text {coord } }\end{array} $和$\begin{array} { c } \lambda _ { \text {nobjd} }\end{array} $来加大定位的训练粒度,包含3个部分:
第一部分为坐标回归,使用平方差损失,为了使得模型更关注小目标的小误差,而不是大目标的小误差,对宽高使用了平方根损失进行变相加权。这里$\mathbb { 1 } _ { i j } ^ { \mathrm { obj } }$指代当前b box是否负责GT的预测,需要满足2个条件,首先GT的中心点在该b box对应的格子中,其次该b box要是对应的格子的个box中与GT的IOU最大
第二部分为b box置信度的回归,$\mathbb { 1 } _ { i j } ^ { \mathrm { obj } }$跟上述一样,$\mathbb { 1 } _ { i j } ^ { \mathrm { nooobj } }$为$$\mathbb { 1 } _ { i j } ^ { \mathrm { obj } }$$的b box,由于负样本数量较多,所以给了个低权重。若有目标,$\begin{array} hat { C }\end{array}$实际为IOU,虽然很多实现直接取1.
第三部分为分类置信度,相对于格子而言,$\mathbb { 1 } _ { i j } ^ { \mathrm { obj } }$指代GT中心是否在格子中
YOLO在ImageNet分类任务上以一半的分辨率(224*224的输入图像)预训练卷积层,然后将分辨 率加倍来进行检测。
训练中采用了drop out和数据增强(data augmentation)来防止过拟合.
总结
开创性的one-stage detector,在卷积网络后面接两个全连接层进行定位和置信度的预测,并设计了一个新的轻量级主干网络,虽然准确率与SOTA有一定距离,但是模型的速度真的很快
作者提到了YOLO的几点局限性:
- 每个格子仅预测一个类别,两个框,对密集场景预测不好
- 对数据依赖强,不能泛化到不常见的宽高比物体中,下采样过多,导致特征过于粗糙
- 损失函数没有完成对大小物体进行区别对待,应该更关注小物体的误差,因为对IOU影响较大,定位错误是模型错误的主要来源