
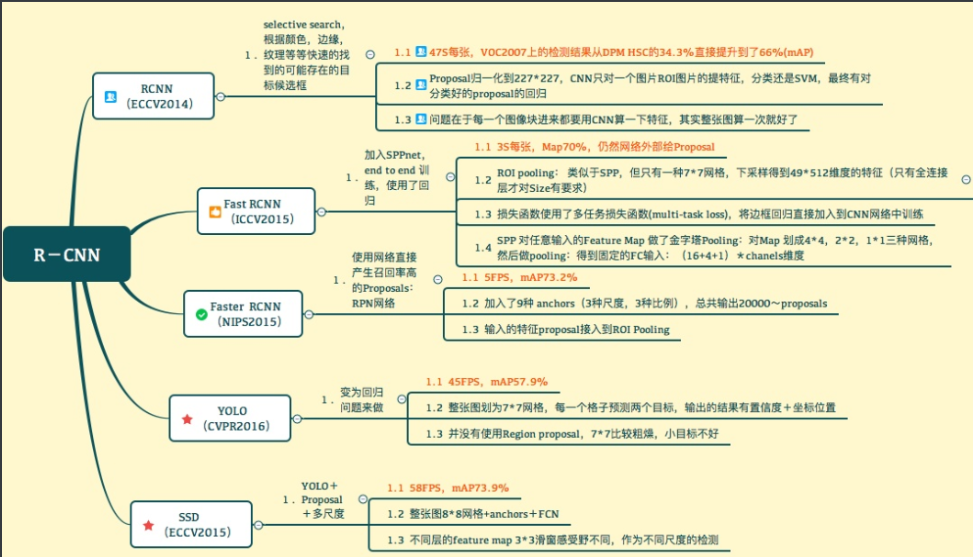
写在前面:之前两个月没有看过cv方向的东西…..所以打算开个系列来写目标检测,图像分割的爆款算法,算是回顾一遍吧,当然一些太经典鼻祖级的模型就懒得看了……于是这个系列就决定叫复健计划了….目标检测的第一篇就从Faster R-CNN开始吧,Faster R-CNN 是目标检测中的一个很经典的two stage算法,许多其他的目标检测算法都会运用到Faster R-CNN的部分结构或思想。而且了解Faster R-CNN对理解其他R-CNN系列网络都有一定的帮助,包括Mask R-CNN,Stereo R-CNN 等等。
概述
Faster R-CNN由R-CNN,Fast R-NN改进演变而来,相对于前两者,Faster R-CNN具有训练速度快,消耗内存减少,精度与检测速度都有大幅提升的优点。
先来一张Faster R-CNN的网络基本结构图 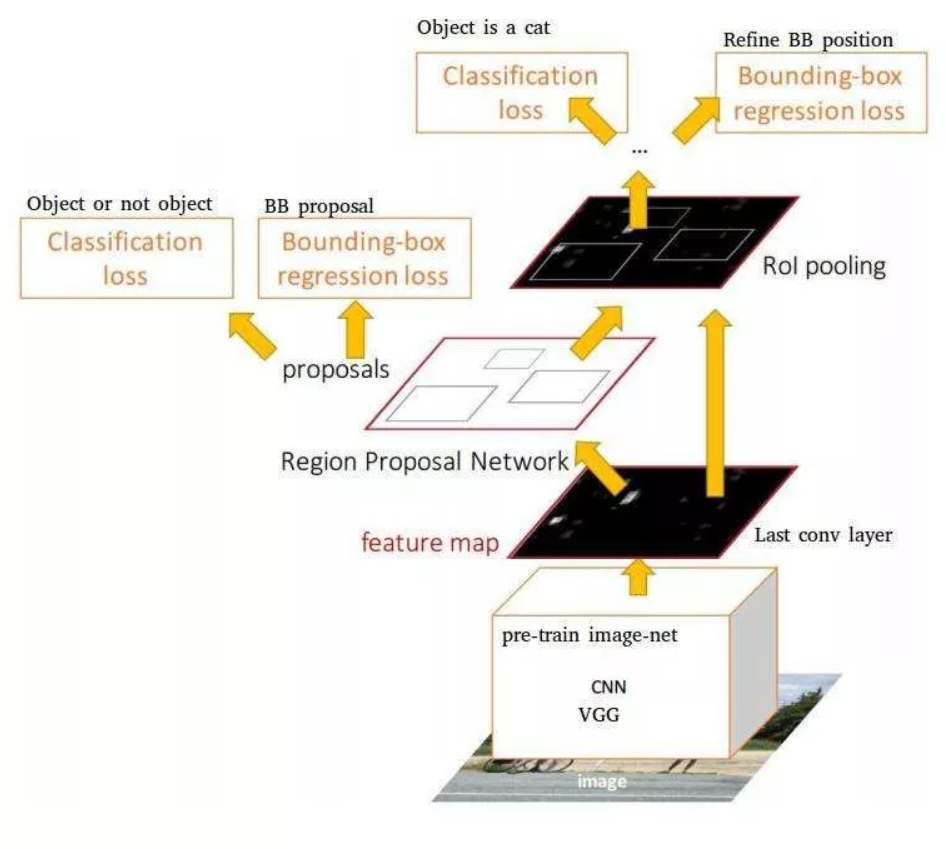
个人认为网络主要分为五个部分:
- 提取feature map(特征图)的Conv layer。该部分使用VGG-net作为预处理网络,运用多个conv,relu,pooling层提取图像特征图,为后面的网络提供图像信息。
- anchor的生成,Faster R-CNN对图像生成一系列的anchor,作为目标检测的先验框,用于多尺度预测,并在后面使用bounding box regression对其位置进行修正。
- RPN(Region Proposal Network),在feature map上的每个点生成anchor,然后将其映射回原图,对原图中的anchor进行修正、筛选,提取该区域的图像(region proposal),也就是所谓的ROI,送进ROI pooing层。
- ROI pooing,对featuer map中的ROI划分为Pool_h*Poo_w(ROI pooling后特征图的高和宽))个网格,对每一个网格进行maxpooling。
- 使用full connection,softmax对ROI进行分类与bounding box回归,确定bounding box的位置。
下面从这五个部分进行说明。先上一个网上总结的Faster R-CNN的结构图。 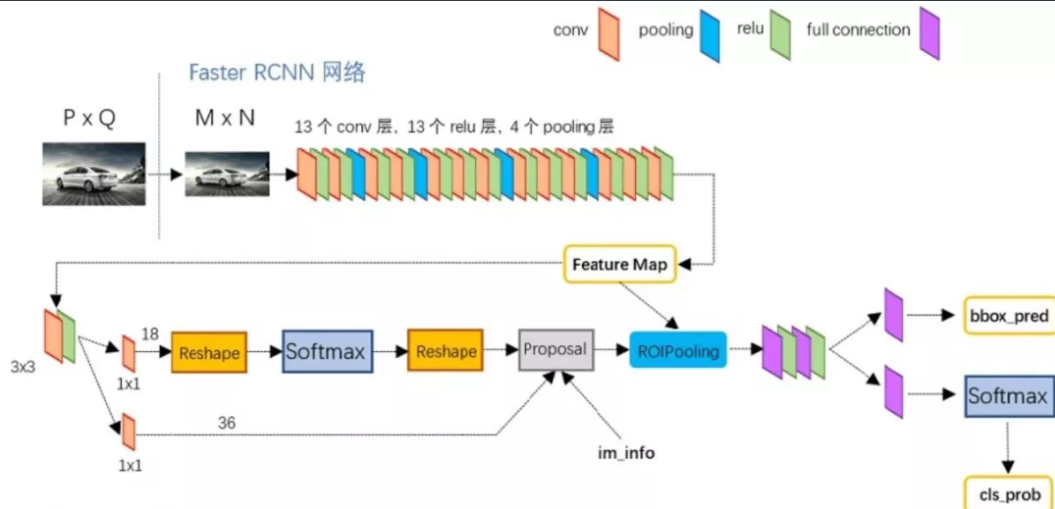
Conv layer
Conv layers包含3种层,分别是conv层,pooling层,relu层。conv层的卷积核大小都是3 * 3 , 步长都为1,并且都做了扩边处理,也就是经过conv层后图像的大小没有改变,只是深度改变。pooling 层的kernel_size=2,步长也为2,也就是说每经过一次pooling层后,图像尺寸减小一半。
Faster RCNN在将图片传入网络之前,会将图片缩放为M * N(VGG 为 800 * 600),从原图到feature map一共经过4次pooling,也就是feature map的大小为(int(M/16),int(N/16))。
anchor
anchor其实是在图像上的一个个先验框,用来对后面检测框的修正以及region proposal。这里说一下anchor的生成过程。
先来看看作者的图 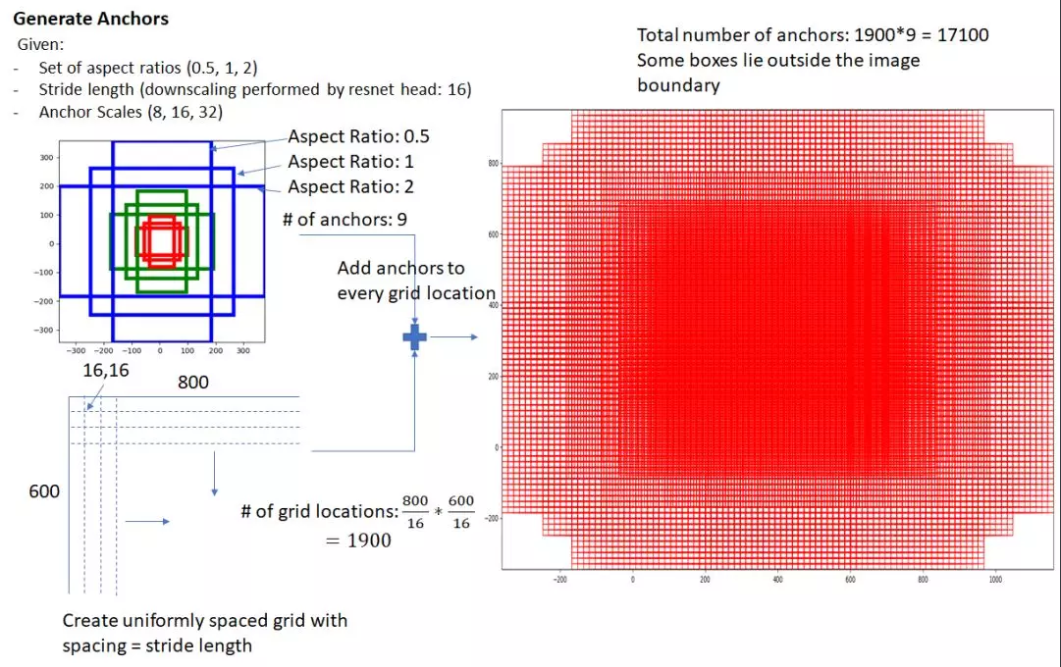
可以看到,anchor的长宽比有[0.5, 1, 2]三种比例,每种anchor有[8, 16, 32]三个尺度比例,所以anchors一共有3 * 3 = 9个anchor。
生成anchor的主要分为一下步骤:
- 首先设置一个16 16的窗口(因为feature map尺寸为原图的1/16,所以一个feature map上的点对应原图上16 16 的区域),计算的到[x_ctr, y_ctr, w, h],也就是anchor的中心点坐标以及长宽4个量。
- 然后计算anchor的面积size = w h,将size分别除[0.5, 1, 2]3种比例,再分别对3个新的sizes开根号作为新的anchor的3个w,再将w [0.5, 1, 2]得到h,这样就得到3个anchor的长宽。
- 将3个anchor长宽分别再乘3个尺度比例,这样就得到9个anchor,再将anchor的表示转换为左上角和右下角的坐标[x_l, y_l, x_r, y_r]。
此时每个feature map上的点都有9个anchor,也就是一共有(800/16)(600/16) 9=17100个anchor。再将这些anchor通过原图与feature map的映射关系,将其anchor映射回原图。 
RPN
RPN的主要结构如图 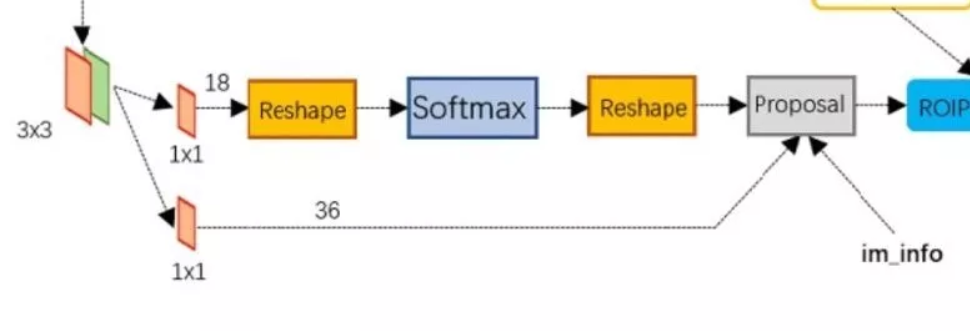
首先将feature map在经过一次conv卷积(这里设得到的网络层为conv5_3),然后分开两条线进行:
- 先将conv5_3使用1 1 18的卷积核对anchor进行softmax分类,将anchor分为postivte和negative(rpn_cls_prob),二分类。(18 = 2(positiv and negative)* 9(9个anchor)。
- 用于预测bounding box的坐标偏移值。
- 在Proposal层综合im_info(主要用来计算proposal的坐标以及限制proposal的大小以免超出图像边框)、rpn_box_pred 和rpn_cls_prob选择和提取ROI。
softmax 分类
conv5_3经过1 1 18 卷积后,维度变为[W, H, 18]。softmax就是要将每个点的9个anchor进行二分类(positive和negative)。softmax前后各有一次reshape,其实只是为了让分类更方便而已,这是训练的一些trick。
bounding box predict
conv5_3经过1 1 36 卷积变为[W, H, 36],第三个维度为每个anchor的2个坐标的偏移量,用于后面的bounding box regression。
bounding box regression
在训练时需要对anchor进行转换才能贴合GT_bbox。怎样转换呢,最简单的做法就是平移加缩放。
下面是转换的关系式:
$$
\begin{aligned}
&t_{x}=\left(x-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, \quad t_{\mathrm{y}}=\left(y-y_{\mathrm{a}}\right) / h_{\mathrm{a}}\
&t_{\mathrm{w}}=\log \left(w / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}=\log \left(h / h_{\mathrm{a}}\right)\
&\begin{aligned}
t_{\mathrm{x}}^{} &=\left(x^{}-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, \quad t_{\mathrm{y}}^{}=\left(y^{}-y_{\mathrm{a}}\right) / h_{\mathrm{a}} \
t_{\mathrm{w}}^{} &=\log \left(w^{} / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}^{}=\log \left(h^{} / h_{\mathrm{a}}\right)
\end{aligned}
\end{aligned}
$$
损失函数为:
$$
\begin{aligned}
L\left(\left{p_{i}\right},\left{t_{i}\right}\right) &=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{}\right) \
&+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{} L_{r e g}\left(t_{i}, t_{i}^{*}\right)
\end{aligned}
$$
ROI proposal
ROI prosposal负责综合所有的关于anchor的变换和对softmax的分类positive anchor,在feature map上计算出精确的ROI,将其送入后面的ROI Pooling层。
主要步骤为:
- 对softmax后的anchor按score进行排序,提取前N个score的anchor。
- 对这些anchor进行修正。
- 修正大于图像边缘的anchor。
- 对w或h小于设定阈值的anchor剔除。

最后传入的ROI类似这样
至此,RPN的任务到此完成。
ROI pooling
Faster RCNN最后的Classification和bounding box 的预测需要用到全连接层,所以在将图片传入全连接层时需要将其变为固定大小。但是一般输入的ROI大小都不固定,如果利用采样的方法进行变换为所需要的大小,会对图像的结构产生影响。

为了解决这个问题,Faster RCNN提出了ROI pooling的方法。
具体方法为:
将ROI划分为pool_h和pool_w个网格。
每个网格的起始和结束坐标计算方法为
1
int hstart = static_cast<int>(floor(ph * bin_size_h)); int wstart = static_cast<int>(floor(pw * bin_size_w)); int hend = static_cast<int>(ceil((ph + 1) * bin_size_h)); int wend = static_cast<int>(ceil((pw + 1) * bin_size_w)); //其中pw,ph是每个网格的坐标值
计算完之后的每个网格可能会有重叠
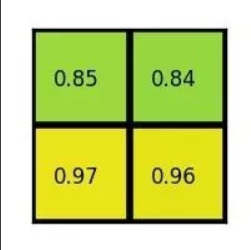
将每个网格进行max pooling操作,这样就得到固定大小的图了。
假设输出为2 * 2 大小
.jpg)
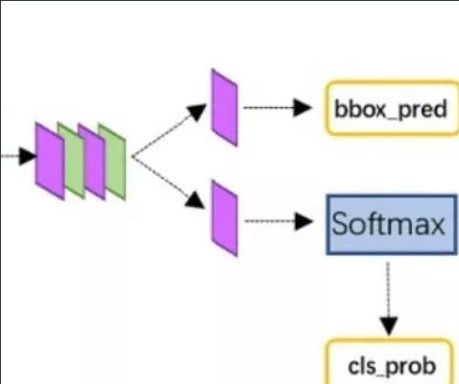
Classification ,bounding box predict
这个没什么好说的了,就是使用全连接层和softmax层进行分类和预测bounding box坐标值。
| 方法 | 创新 | 缺点 | 改进 |
|---|---|---|---|
| R-CNN (Region-based Convolutional Neural Networks) | 1、SS提取RP; 2、CNN提取特征; 3、SVM分类; 4、BB盒回归。 | 1、 训练步骤繁琐(微调网络+训练SVM+训练bbox); 2、 训练、测试均速度慢 ; 3、 训练占空间 | 1、 从DPM HSC的34.3%直接提升到了66%(mAP); 2、 引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) | 1、SS提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 | 1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s); 2、 无法满足实时应用,没有真正实现端到端训练测试; 3、 利用了GPU,但是区域建议方法是在CPU上实现的。 | 1、 由66.9%提升到70%; 2、 每张图像耗时约为3s。 |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) | 1、RPN提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归 | 1、 还是无法达到实时检测目标; 2、 获取region proposal,再对每个proposal分类计算量还是比较大。 | 1、 提高了检测精度和速度; 2、 真正实现端到端的目标检测框架; 3、 生成建议框仅需约10ms。 |