
主要观点:CSRnet网络模型主要分为前端和后端网络,采用剔除了全连接层的VGG-16作为CSRnet的前端网络,输出图像的大小为原始输入图像的1/8。卷积层的数量增加会导致输出的图像变小,从而增加生成密度图的难度。所以本文采用空洞卷积神经网络作为后端网络,在保持分辨率的同时扩大感知域, 生成高质量的人群分布密度图。
1、MCNN的多列设计没有显著作用:
以前的拥挤场景分析工作主要基于multi-scale architectures。它们在该领域取得了很高的性能,但是当网络变得更深时,它们使用的设计也带来了两个显着的缺点:大量的训练时间和无效的分支结构(例如,MCNN )。我们设计了一个实验来证明MCNN与表1中更深入的常规网络相比表现不佳。
如我们先前所知,MCNN的每列专用于某一级别的拥塞场景。但是,使用MCNN的有效性可能并不突出。我们在图2中展示了MCNN中三个独立列(代表大,中,小的感受野)所学习的特征,并用ShanghaiTech Part A [18]数据集进行评估。该图中的三条曲线与具有不同拥塞密度的50个测试案例共享非常相似的模式(估计的错误率),这意味着这种分支结构中的每个列学习几乎相同的特征。它违背了MCNN设计的初衷,用于学习每列的不同功能。
2、膨胀卷积优于反卷积
已经在分割任务中证明了膨胀卷积层,其精度得到显着提高,并且它是池化层的良好替代方案。 尽管池化层(例如,最大和平均池化)被广泛用于维持不变性和控制过度拟合,但是它们还显着地降低了空间分辨率,这意味着丢失了特征映射的空间信息。 反卷积层可以减轻信息的丢失,但额外的复杂性和执行延迟可能并不适合所有情况。 膨胀卷积是一个更好的选择,它使用稀疏内核(如图3所示)来交替汇集和卷积层。 该字符在不增加参数数量或计算量的情况下扩大了感受野(例如,添加更多卷积层可以产生更大的感受野但引入更多操作)。
为了保持特征图的分辨率,与使用卷积+池化+反卷积的方案相比,膨胀卷积显示出明显的优点。我们在图4中选择一个例子用于说明。输入是人群的图像,并且它分别通过两种方法处理以产生具有相同大小的输出。在第一种方法中,输入由具有因子2的最大池化层进行下采样,然后将其传递到具有3X3 Sobel内核的卷积层。由于生成的特征映射仅是原始输入的1/2,因此需要通过解卷积层(双线性插值)bilinear interpolation对其进行上采样。在另一种方法中,我们尝试扩张卷积并使相同的3X3 Sobel内核适应具有因子= 2步幅的扩张内核。输出与输入共享相同的维度。最重要的是,扩张卷积的输出包含更详细的信息。
贡献:
在本文中,我们设计了一个更深入的网络,称为CSR-Net,用于计算人群和生成高质量的密度图。我们的模型使用纯卷积层作为主干,以灵活的分辨率支持输入图像。为了限制网络的复杂性,我们在所有层中使用小尺寸的卷积滤波器(如3x3)。我们将VGG-16 [21]的前10层作为前端和膨胀卷积层作为后端部署,以扩大感受域并提取更深的特征而不会丢失分辨率(因为不使用池化层)。
主要实现:
网络结构:
此前端网络的输出大小是原始输入大小的1/8。如果我们继续堆叠更多卷积层和池化层(VGG-16中的基本组件),输出大小将进一步缩小,并且很难生成高质量的密度映射。 我们尝试将膨胀卷积层作为后端来提取更深层的显着性信息以及维持输出分辨率。
我们在表3中提出了四种CSRNet网络配置,它们具有相同的前端结构但后端的扩展速率不同。 关于前端,我们采用VGG-16网络(全连接层除外)并仅使用3X3内核。 根据VGG的论文,当使用相同大小的感受野时,使用具有小内核的更多卷积层比使用具有更大内核的更少层更有效。
通过移除完全连接的层,我们尝试确定需要从VGG-16使用的层数。 最关键的部分是在准确性和资源开销(包括训练时间,内存消耗和参数数量)之间进行权衡。 实验表明,在保持前十层VGG-16 [21]只有3个池化层而不是五层时,可以实现最佳权衡,以抑制由池化操作引起的对输出精度的不利影响。 由于CSRNet的输出(密度图)较小(输入尺寸的1/8),我们选择因子为8的双线性插值进行缩放,并确保输出与输入图像具有相同的分辨率。 使用相同的大小,CSRNet生成的结果与使用PSNR(峰值信噪比)和SSIM(图像中的结构相似性)的基础事实结果相当。
数据增强:
我们从不同位置的每个图像裁剪9个patches,原始图像的大小为1/4。 前四个patches包含四分之三的图像而没有重叠,而其他五个patches则从输入图像中随机裁剪。 之后,我们镜像patches,以便我们将训练集加倍。
损失函数:
使用简单的方法将CSRNet作为端到端结构进行培训。 前10个卷积层由训练有素的VGG-16进行微调[21]。 对于其他层,初始值来自具有0.01标准偏差的高斯初始化。 随机梯度下降(SGD)在训练期间以1e-6的固定学习率应用。 此外,我们选择欧氏距离来测量地面实况与我们生成的估计密度图之间的差异,这与其他工作类似[19,18,4]。
我们还使用和来评估ShanghaiTech Part A数据集上输出密度图的质量。 为了计算和,我们遵循[5]给出的预处理,其中包括密度图调整大小(与原始输入相同的大小),对地面实况和预测密度图进行插值和归一化。 除了人群计数之外,我们在TRANCOS数据集[44]上设置了一个实验,用于车辆计数,以证明我们的方法的稳健性和一般化。 TRANCOS是一个公共交通数据集,包含由监控摄像机捕获的1244个不同拥挤交通场景的图像,其中包含46796个带注释的车辆。 此外,提供感兴趣区域(ROI)用于评估。 图像的视角不固定,图像是从非常不同的场景中收集的。 网格平均值平均绝对误差(GAME)[44]用于此测试中的估值。 GAME定义如下:
代码:https://github.com/leeyeehoo/CSRNet-pytorch
我在根据作者的github(https://github.com/leeyeehoo/CSRNet-pytorch), 构建环境时遇到了一些问题。我调试过,百度花了很长时间才解决。写这一章的目的是帮助大家学得更好,少走弯路。
step1. install
For the specific installation process, you can refer to the author’s github. Here I simply show the command line of my operation.
1 | conda create -n CSRNet python=3.6 |
step2. make_dataset.py
I just run the command to convert the make_dataset.ipynb file to a make_dataset.py file.Now you need to modify the contents of the make_dataset.py file.
Find the location where root is, add def main() in the above line

Add these two lines at the end of the make_dataset.py, adjust the format of the code

There is an error in the author’s source code, you need to change the code
Replace pts = np.array(zip(np.nonzero(gt)[1], np.nonzero(gt)[0])) with pts = np.array(list(zip(np.nonzero(gt)[1], np.nonzero(gt)[0])))
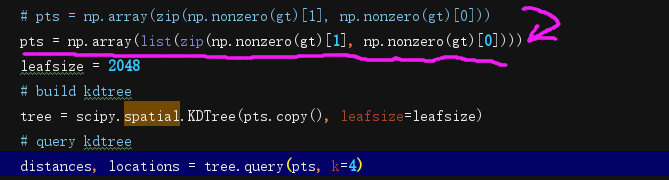
Then run the make_dataset.py file
The above is just a general summary, then we will run and visualize the line-by-line code.
I will use this image as an example.
1 | # coding: utf-8 |
The following is the information of k
1 | gt = mat["image_info"][0,0][0,0][0] |
1 | for i in range(0,len(gt)): |
1 | density = np.zeros(gt.shape, dtype=np.float32) |
1 | gt_count = np.count_nonzero(gt) |

1 | pts = np.array(list(zip(np.nonzero(gt)[1], np.nonzero(gt)[0]))) |
1 | leafsize = 2048 |
1 | distances, locations = tree.query(pts, k=4) |
1 | print('generate density...') |
1 | k = density |

So far, we have generated true values for the image. At this point I will sort the above code as follows
1 | # coding: utf-8 |
And….then, let’s plot the true values of the image:
1 | gt_file = h5py.File(img_paths[0].replace('.jpg','.h5').replace('images','ground_truth'),'r') |

1 | groundtruth = np.asarray(gt_file['density']) |
plot the true values of the image
1 | plt.imshow(groundtruth,cmap=CM.jet) |
Calculate how many people are in this picture
1 | np.sum(groundtruth) |
Based on the same operation above, I generated true values for all images in the dataset. The following operations are performed on the gpu server.
That is, run the command line python make_dataset.py on the server to get the true value of all the pictures.
step3. Training
Note: if you use the python3.x
1 | 1. In model.py, change the xrange in line 18 to range |
- In part_A_train.json:change the path of images
- In part_A_val.json: change the path of images
run
1 | python train.py part_A_train.json part_A_val.json 0 0 |
step4. Testing
These are our test images. number:182
1 | jupyter nbconvert --to script val.ipynb |
Finally, the performance of this model on invisible data is tested. We will use the val.py file to verify the results. Remember to change the path to pre-train weights and images.
1 | python val.py |
The average absolute error value that can be obtained by running this val.py file code
total :182
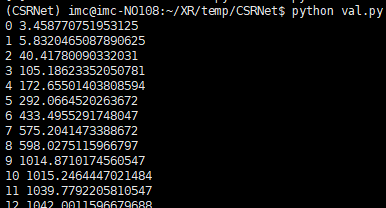
The average absolute error value obtained is 65.96636956602663, which is very good.
Now let’s examine the predicted values on a single image:
run
1 | python test_single-image.py |
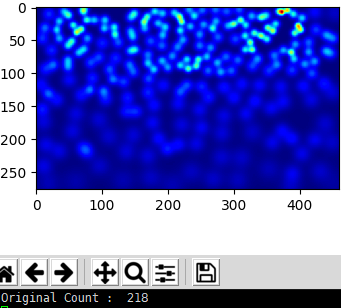

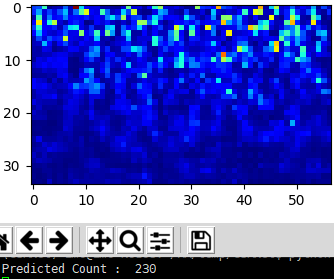
another one
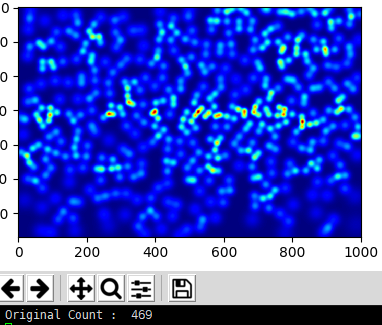

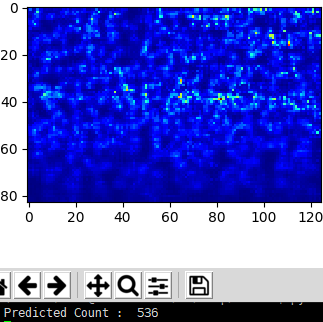
The effect is not too good,maybe the model is not trained enough,i guess。
Reading paper https://arxiv.org/pdf/1802.10062.pdf
先说数据集用的ShanghaiTech dataset,根据.jpg和.mat处理之后生成train_den文件夹下.csv文件和图片一一对应 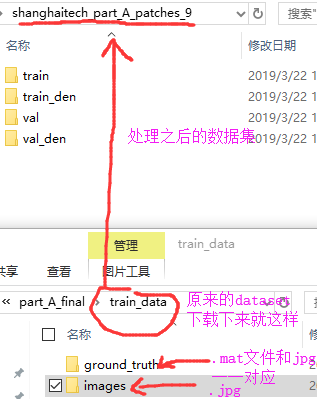
数据集扩充处理再补充一下:使用的是高斯模糊作用于图像中的每个人的头部。所有图像都被裁剪成9块,每块的大小是图像原始大小的1/4。
空洞卷积也有的博客翻译成膨胀卷积、扩张卷积啥的,anyway,使用扩张卷积是在不增加参数的情况下扩大内核。因此,如果扩张率为1就是中间的图在整个图像上进行卷积。将膨胀率增加到2最右边图它可以替代pooling层
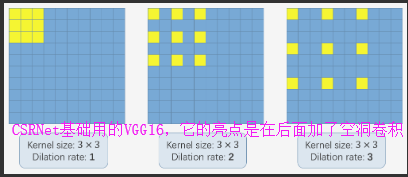
接下来再说它的数学公式上怎么计算的,

由上公式得到这个([k + (k-1)(r-1)] [k + (k-1)*(r-1)])




这个过程是:首先预测出给定图像的密度图。如果没有人,像素值pixel value设为0。如果该像素对应于人,则将分配某个预定义值。所以图像中的人数就是总共有的像素值total pixel values